Alignement des caractéristiques polynomiales avec la distribution des données : Le problème de l'attention-alignement en ML
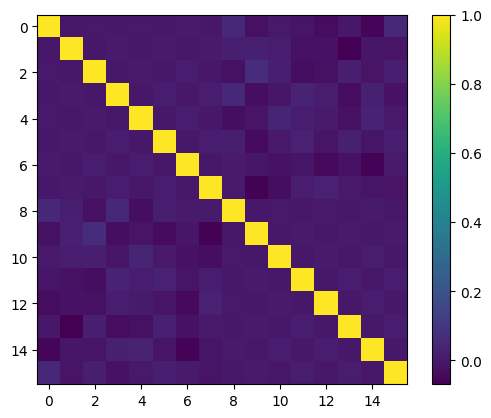
Cet article explore l'alignement des caractéristiques polynomiales avec la distribution des données pour améliorer les performances du modèle d'apprentissage automatique. Les bases orthogonales produisent des caractéristiques informatives lorsque les données sont distribuées uniformément, mais ce n'est pas le cas des données réelles. Deux approches sont présentées : une astuce de mapping, qui transforme les données en une distribution uniforme avant d'appliquer une base orthogonale ; et la multiplication par une fonction soigneusement choisie pour ajuster la fonction de poids de la base orthogonale afin qu'elle s'aligne sur la distribution des données. La première est plus pratique, réalisable avec le QuantileTransformer de Scikit-Learn. La seconde est plus complexe, nécessitant une compréhension mathématique plus approfondie et des réglages fins. Les expériences sur l'ensemble de données des logements en Californie montrent que les caractéristiques quasi-orthogonales de la première méthode surpassent le scaling min-max traditionnel dans la régression linéaire.