Efficient Fine-tuning: A Deep Dive into LoRA (Part 1)
2024-12-25
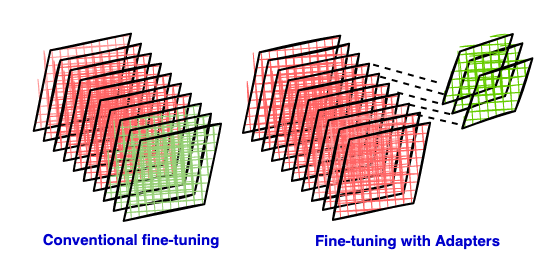
Fine-tuning large language models typically requires substantial computational resources. This article introduces LoRA, a parameter-efficient fine-tuning technique. LoRA significantly reduces the number of parameters needing training by inserting low-rank matrices as adapters into a pre-trained model, thus lowering computational and storage costs. This first part explains the principles behind LoRA, including the shortcomings of traditional fine-tuning, the advantages of parameter-efficient methods, and the mathematical basis of low-rank approximation. Subsequent parts will delve into the specific implementation and application of LoRA.