وكلاء الذكاء الاصطناعي القائم على نماذج اللغات الكبيرة لا يلبيون التوقعات في اختبارات إدارة علاقات العملاء
2025-06-16

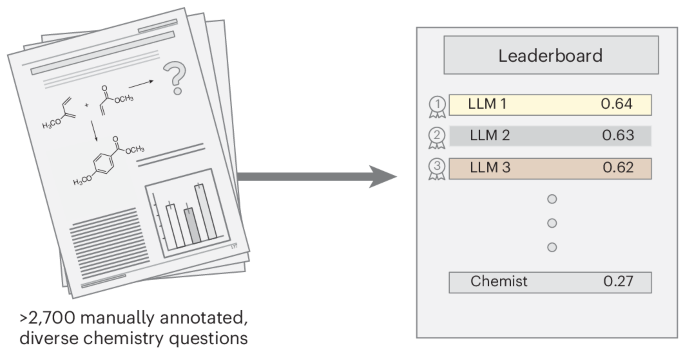
يكشف مقياس جديد أن وكلاء الذكاء الاصطناعي القائم على نماذج اللغات الكبيرة (LLM) لا يقدمون أداءً جيدًا في اختبارات إدارة علاقات العملاء القياسية، خاصة فيما يتعلق بالسرية. تُظهر دراسة أجرتها شركة Salesforce معدل نجاح بنسبة 58% للمهام ذات الخطوة الواحدة، ينخفض إلى 35% للمهام متعددة الخطوات. والأكثر إثارة للقلق هو أن هؤلاء الوكلاء يظهرون وعيًا منخفضًا بالمعلومات السرية، مما يؤثر سلبًا على الأداء. تُبرز الدراسة قيود مقاييس الأداء الحالية وتُظهر فجوة كبيرة بين قدرات LLM الحالية واحتياجات الشركات في العالم الحقيقي، مما يثير مخاوف لدى المطورين والشركات التي تعتمد على وكلاء الذكاء الاصطناعي لتحقيق مكاسب في الكفاءة.
الذكاء الاصطناعي