SIMD関数:コンパイラの自動ベクトル化のメリットとリスク
2025-07-05
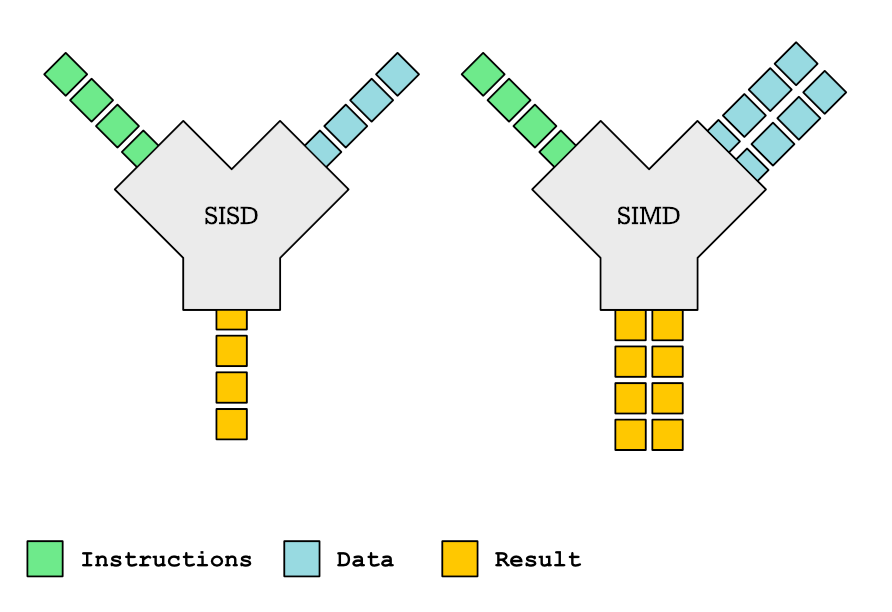
この記事では、SIMD関数とコンパイラの自動ベクトル化における役割について詳しく説明します。複数のデータ点を同時に処理できるSIMD関数は、パフォーマンスの大幅な向上をもたらします。しかし、コンパイラのSIMD関数に対するサポートは不均一であり、生成されたベクトル化コードは驚くほど非効率的になる可能性があります。この記事では、OpenMPプラグマとコンパイラ固有の属性を使用してSIMD関数を宣言および定義する方法を詳細に説明し、さまざまなパラメータータイプ(変数、一様、線形)がベクトル化効率に与える影響を分析します。また、インライン関数処理やコンパイラの特性に対処する方法についても説明します。パフォーマンス向上という大きな可能性を秘めている一方で、SIMD関数の実際的な適用には大きな課題があります。
続きを読む
開発


