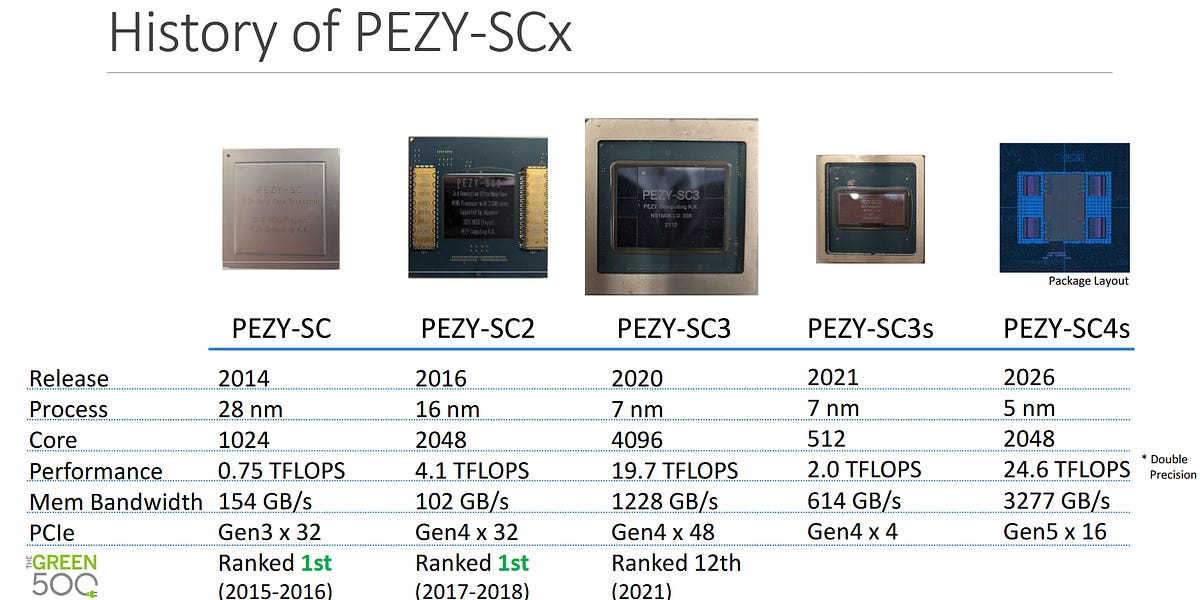
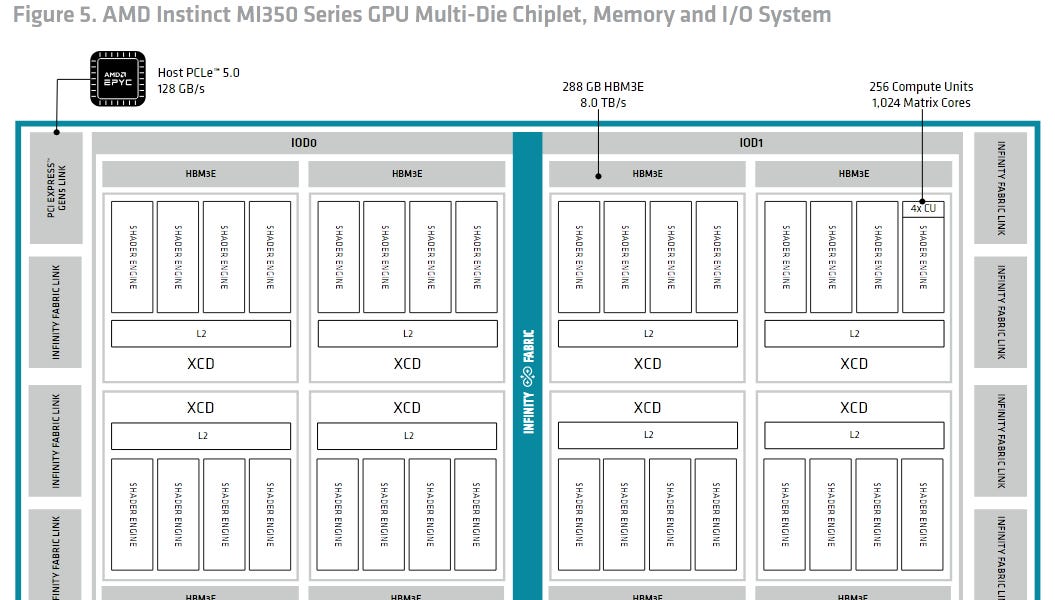
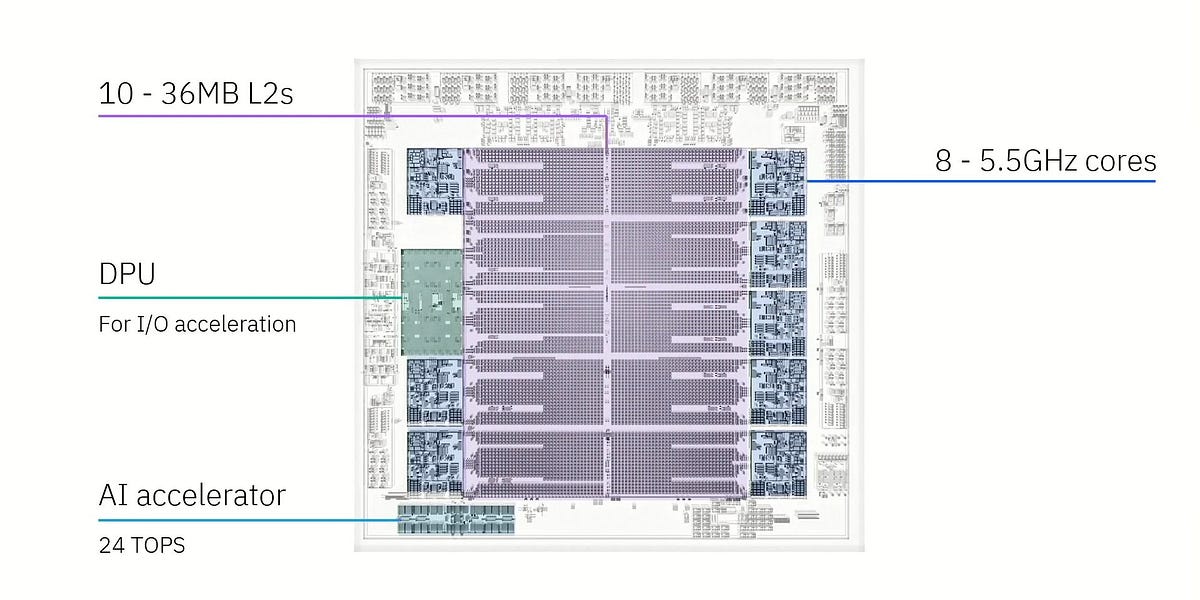
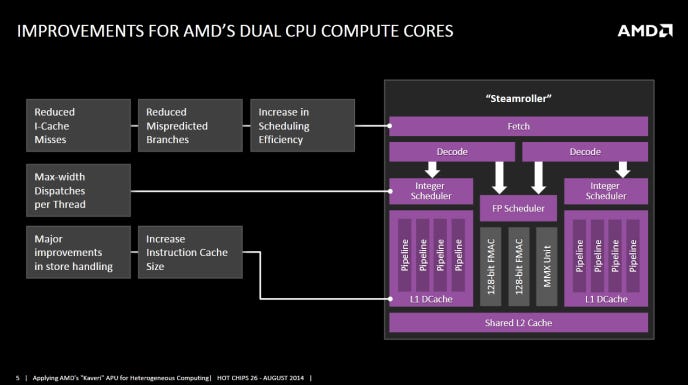
AMD RDNA4: Eficiência acima de tudo na nova arquitetura de GPU

A mais recente arquitetura RDNA4 da AMD prioriza a eficiência em vez do desempenho bruto. As GPUs da série RX 9000 com RDNA4 oferecem melhorias significativas de eficiência em ray tracing e aprendizado de máquina, além de aprimorar a rasterização. As melhorias incluem compressão aprimorada, um mecanismo de mídia mais rápido (compatível com codecs H.264, H.265 e AV1 com latência reduzida) e um mecanismo de exibição atualizado (integrando o filtro de nitidez Radeon Image Sharpening). O RDNA4 se destaca no consumo de energia, especialmente no consumo de energia inativo em monitores múltiplos. Ganhos adicionais de desempenho e eficiência vêm de um processador de grupo de trabalho aprimorado, cache L2 maior e arquitetura Infinity Fabric otimizada. Em resumo, o RDNA4 representa um salto significativo no design de GPU da AMD, priorizando a eficiência para oferecer uma experiência mais equilibrada e eficiente em termos de energia para jogadores e profissionais.
Leia mais