批量奖励模型推理和最佳N采样
2024-11-19
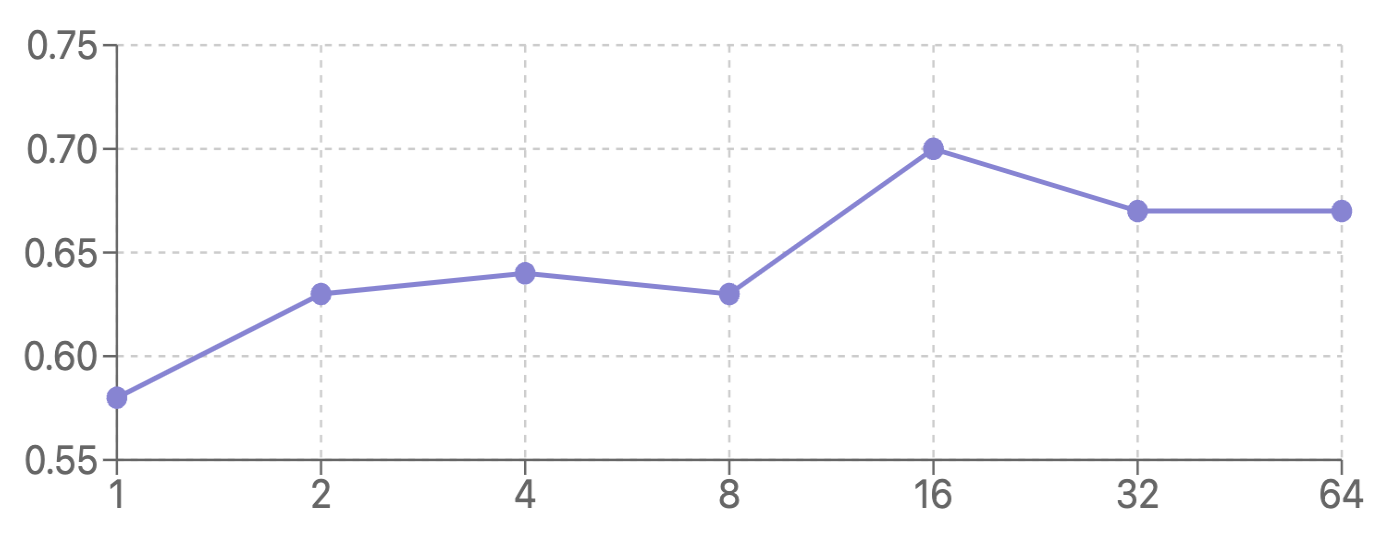
文章介绍了如何使用Mixedbread库进行高效的批量奖励模型推理,以及如何利用Modal部署奖励模型API。作者使用了RLHFlow/ArmoRM-Llama3-8B-v0.1奖励模型,并通过TruthfulQA数据集的子集对其进行了评估,结果显示正确答案的平均排名为2.10,排名第一的概率为53%。此外,文章还探讨了最佳N采样方法,发现使用奖励模型和最佳16采样可以使Llama-3.1-8B-Instruct的零样本准确率提高20.7%。
(raw.sh)
12
未分类
最佳N采样