高效微调:LoRA技术详解(第一部分)
2024-12-25
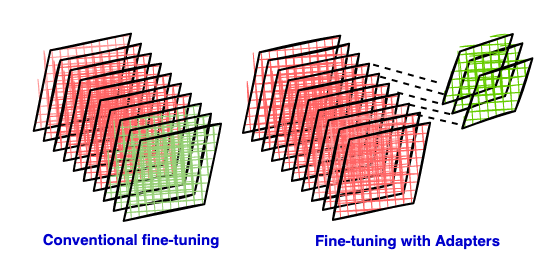
大型语言模型的微调通常需要大量计算资源。本文介绍了一种参数高效的微调技术——LoRA。LoRA通过在预训练模型中插入低秩矩阵(rank deficient matrices)作为适配器,仅训练这些适配器参数,从而大幅减少训练所需的参数量,降低计算和存储成本。这部分文章主要解释了LoRA背后的原理,包括传统微调方法的缺点,参数高效微调方法的优势,以及低秩逼近的数学基础。后续部分将深入探讨LoRA的具体实现和应用。
AI
参数高效微调