大型语言模型微调:是知识注入还是破坏性覆盖?
2025-06-11
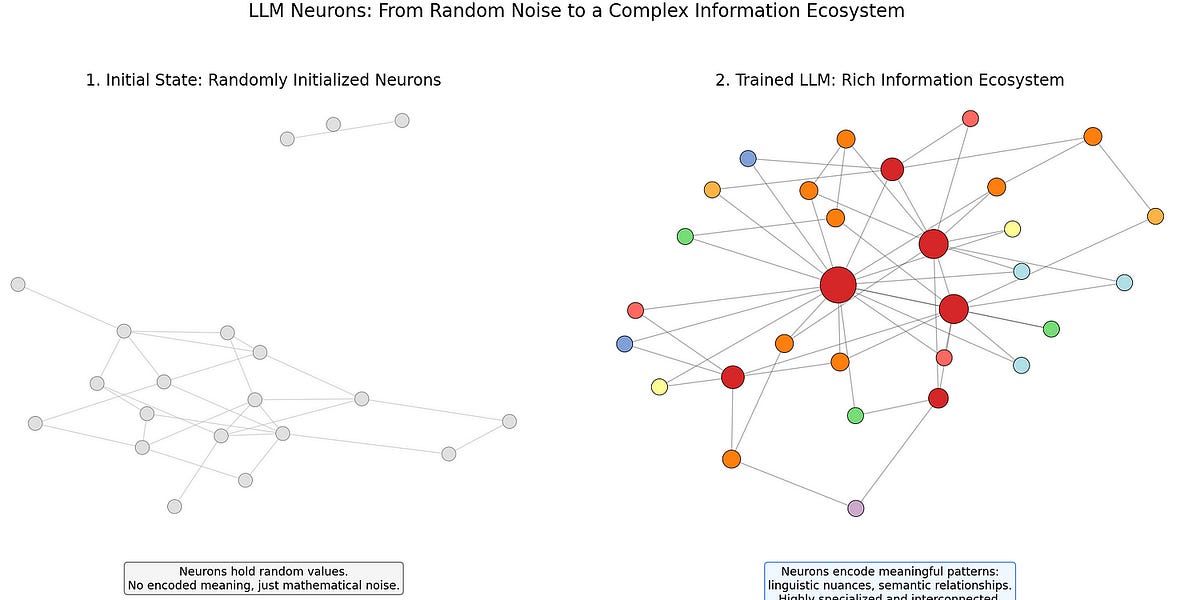
本文揭示了大型语言模型(LLM)微调的局限性。作者指出,对于高级LLM,微调并非简单的知识注入,而是可能破坏已有的知识结构。文中深入解释了神经网络的工作机制,并阐述了微调如何导致现有神经元中重要信息的丢失,从而引发意想不到的后果。作者建议采用模块化方法,如检索增强生成(RAG)、适配器模块和提示工程等,来更有效地注入新知识,避免破坏模型的整体结构。
阅读更多
AI
知识注入