Kangaroo:高效缓存海量微小对象的闪存缓存
2025-05-22

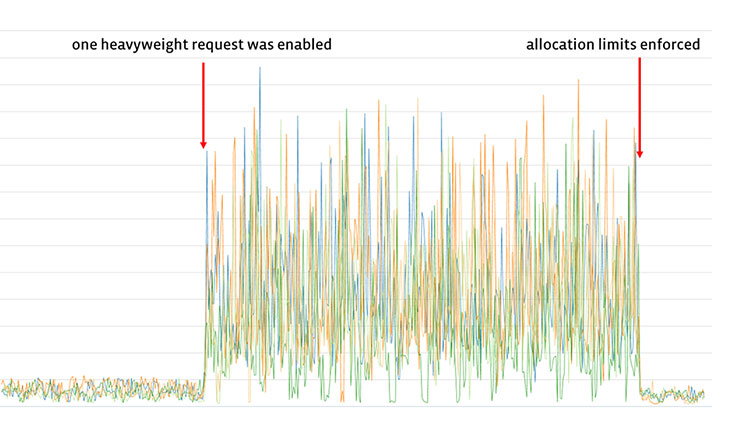
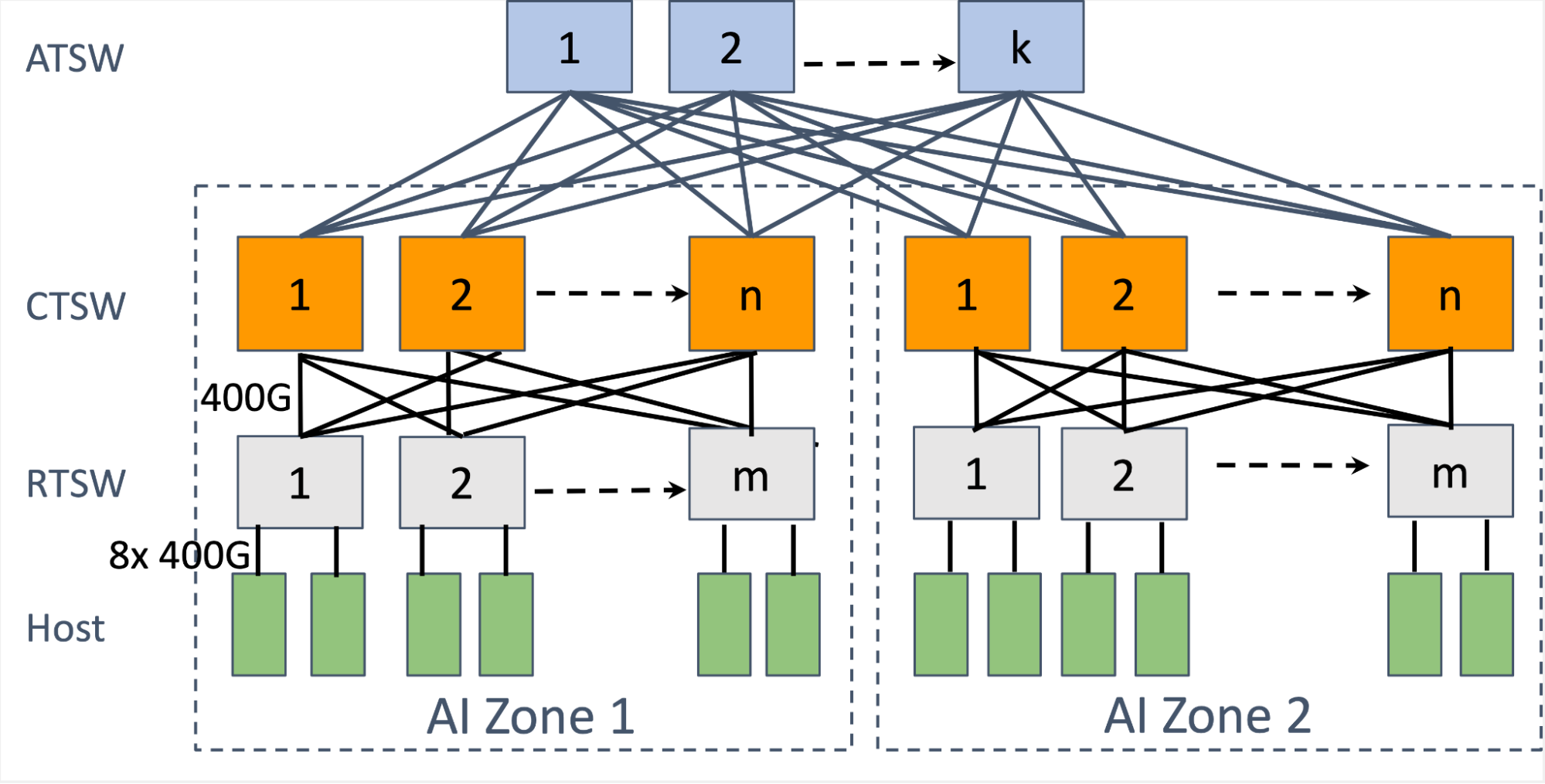
Facebook 和卡内基梅隆大学合作研发了一种名为 Kangaroo 的新型闪存缓存,它能够高效缓存极小的对象(约 100 字节或更小)。Kangaroo 解决了现有闪存缓存设计中 DRAM 使用过多和写入次数过多的难题,通过在 Facebook 开源缓存引擎 CacheLib 中实现,开发者可轻松集成。实验表明,Kangaroo 将缓存未命中率降低了 29%,显著减轻了后端存储系统的负载,特别适用于社交媒体等需要处理大量微小对象的场景。
阅读更多