SIMD 函数:编译器自动向量化的利与弊
2025-07-05
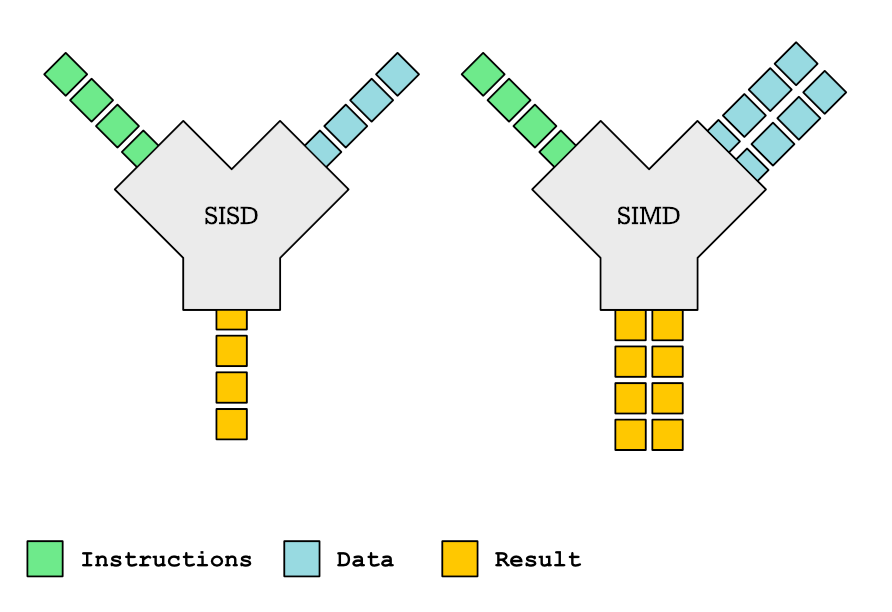
本文深入探讨了 SIMD 函数在编译器自动向量化中的作用。SIMD 函数可以一次处理多个数据,从而提升性能。然而,编译器对 SIMD 函数的支持参差不齐,且生成的向量化代码效率有时并不理想。文章详细介绍了声明和定义 SIMD 函数的方法,包括使用 OpenMP pragma 和自定义编译器属性,并分析了不同参数类型(variable、uniform、linear)对向量化效率的影响。此外,文章还讲解了如何使用 intrinsics 提供自定义的向量化实现,以及处理函数内联和编译器 quirks 的方法。总而言之,虽然 SIMD 函数具有提升性能的潜力,但在实际应用中仍面临诸多挑战。
阅读更多
开发


