OCR自动化基准测试:98%精度下的自动化难题
2025-03-14
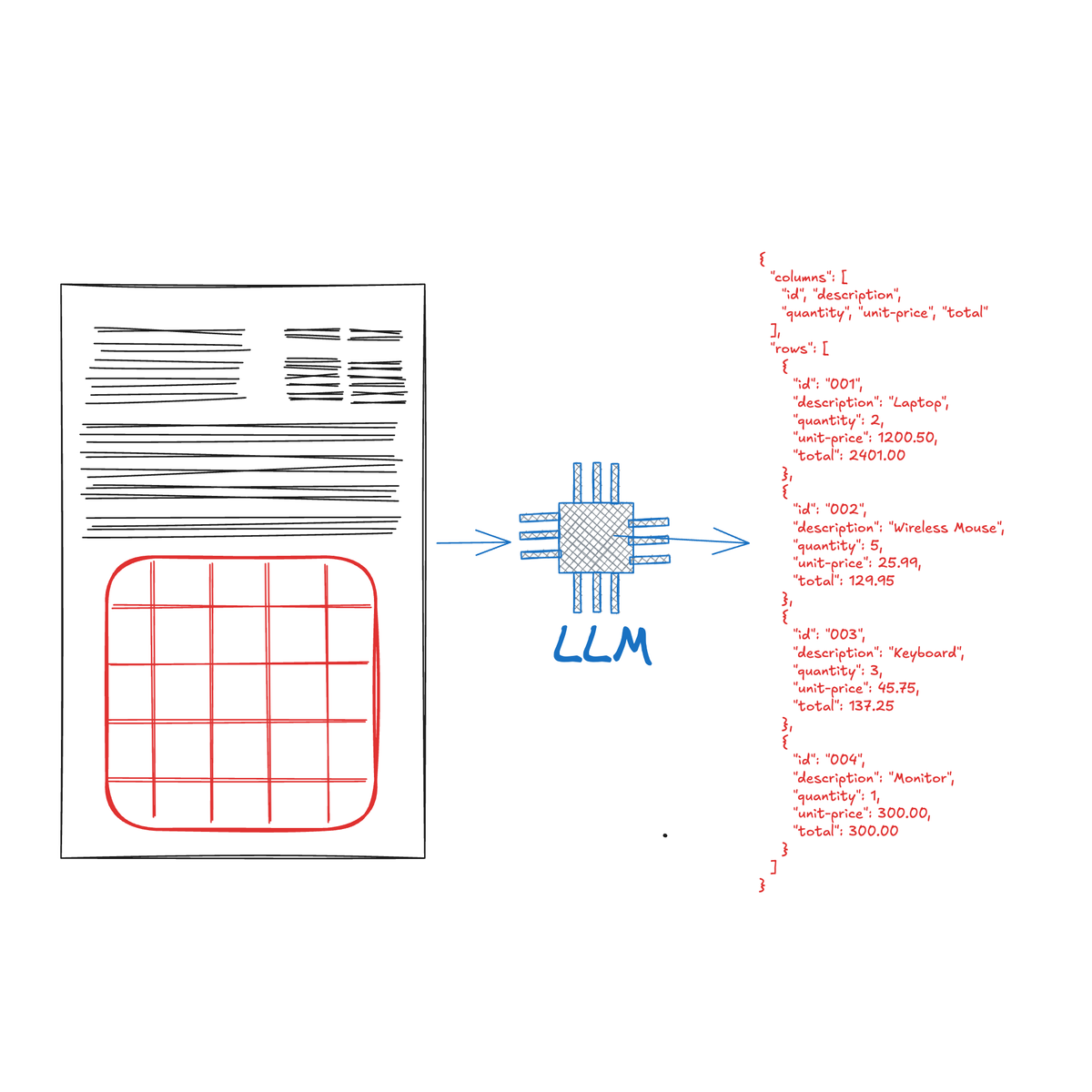
随着Mistral和Andrew Ng等新玩家进入OCR市场,企业面临着难以区分有效声明和夸大宣传的挑战。现有基准测试关注OCR精度和信息提取,但忽略了自动化程度。Nanonets团队创建了一个新的基准测试,重点关注98%精度下的自动化率。他们收集了1000张图像,标注了16639个数据点,并使用置信度评分来衡量模型在无需人工干预的情况下准确处理数据的比例。结果显示,虽然大型语言模型在整体准确率上表现出色,但在提供可靠的置信度评分方面却存在不足,Gemini 2.0 Flash是唯一达到98%精度的模型,但只能自动化8%的数据。该基准测试旨在帮助企业识别真正能减少人工操作的解决方案。
阅读更多
开发