RDNA3 GPU上的FP32矩阵乘法优化:超越rocBLAS 60%
2025-03-28
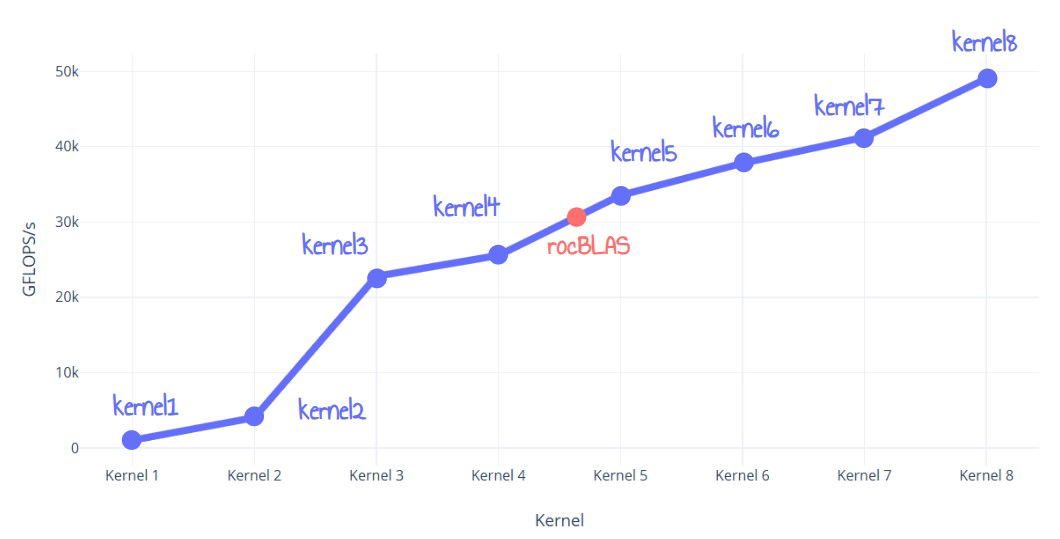
本文详细介绍了如何在AMD RDNA3 GPU上编写优化的FP32矩阵乘法,其性能比rocBLAS快60%。作者通过迭代的方式,逐步优化了8个不同的内核,从简单的朴素实现到最终利用指令集级优化,大幅提升了性能。优化策略包括LDS平铺、寄存器平铺、全局内存双缓冲、LDS利用率优化以及指令集级VALU利用率优化和循环展开等。最终实现的内核性能超过了rocBLAS,达到了近50 TFLOPS。
阅读更多
开发
RDNA3