Observabilité pour GitHub Actions avec OpenTelemetry
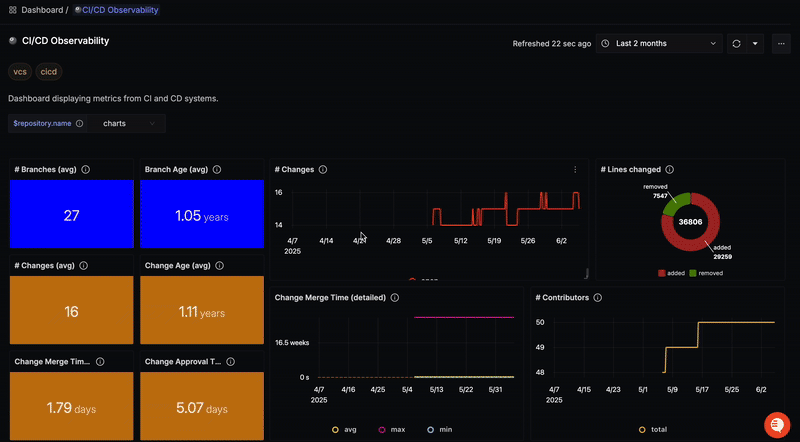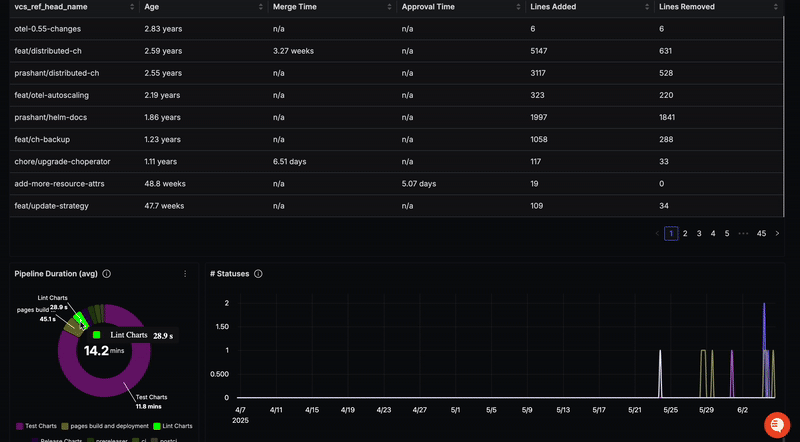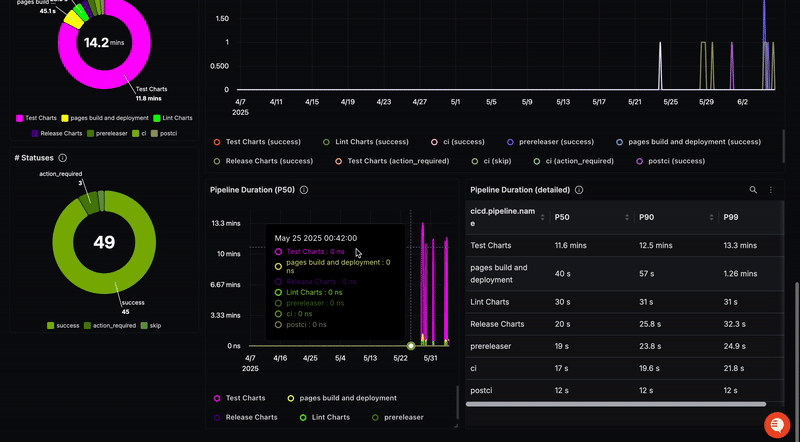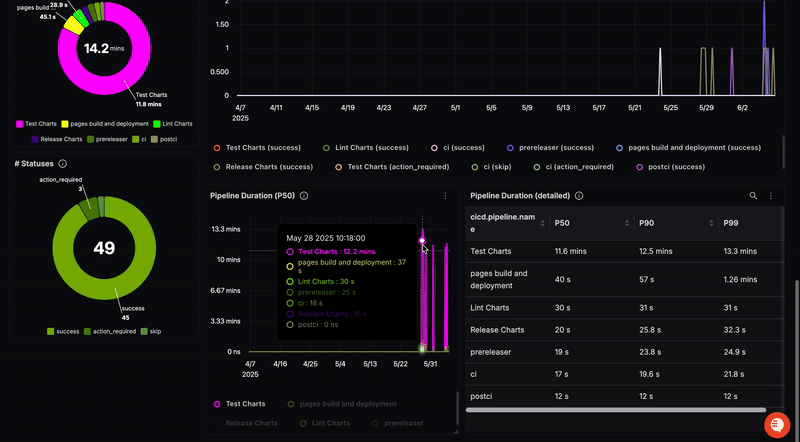
Ce guide montre comment obtenir une observabilité de bout en bout de vos pipelines CI/CD en utilisant OpenTelemetry pour surveiller GitHub Actions. En configurant le récepteur GitHub de l'OpenTelemetry Collector, vous pouvez collecter des traces et des métriques de vos workflows, vous permettant d'identifier les goulots d'étranglement, de déboguer les erreurs et d'analyser les dépendances. Le guide fournit une configuration étape par étape, y compris la configuration d'un webhook GitHub, l'installation de l'OpenTelemetry Collector, la configuration des récepteurs et des processeurs, et la gestion de l'authentification. Des extraits de configuration YAML sont inclus. Enfin, ces données sont envoyées à une plateforme d'observabilité comme SigNoz pour la visualisation et l'analyse.