Figma Slides:一场技术演示的滑铁卢
2025-06-01
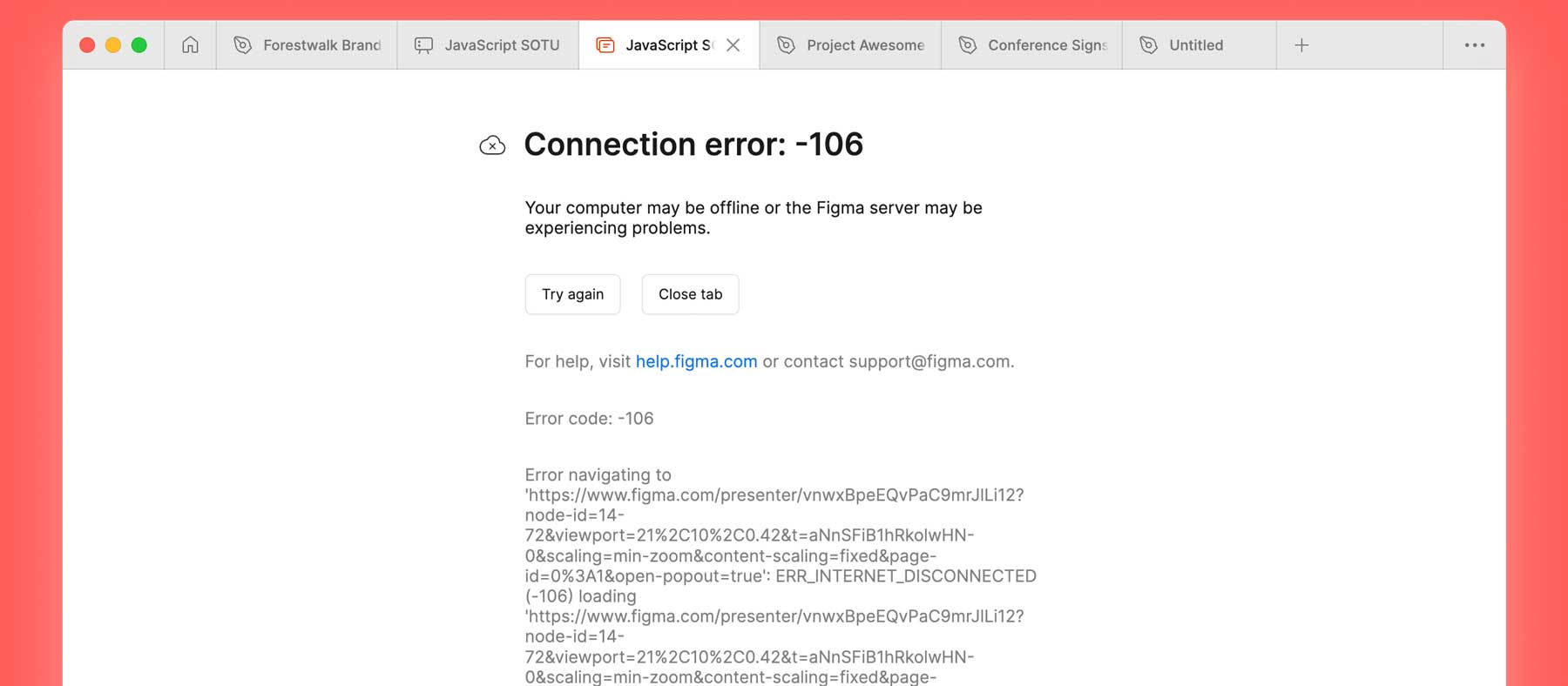
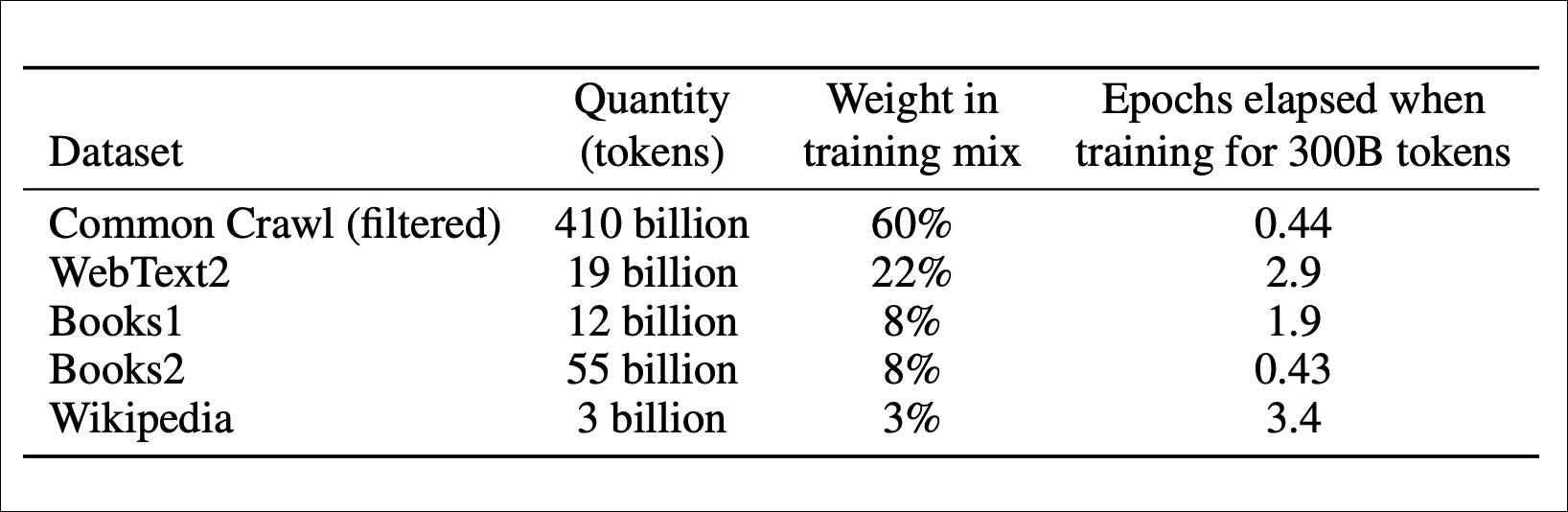
作者尝试使用Figma Slides制作演示文稿,初体验惊艳:强大的网格视图、自动布局和组件功能让制作过程高效便捷。然而,实际演示却遭遇滑铁卢:离线模式下无法正常播放,动画效果异常,甚至需要反复点击才能推进幻灯片。与之形成鲜明对比的是,作者多年来一直使用的Keynote,尽管功能相对简单,却始终稳定可靠。最终,作者以亲身经历证明了“可靠的旧技术”的价值。
阅读更多