AI模型的普适性:通往鲸鱼语言解码之路?
2025-07-18
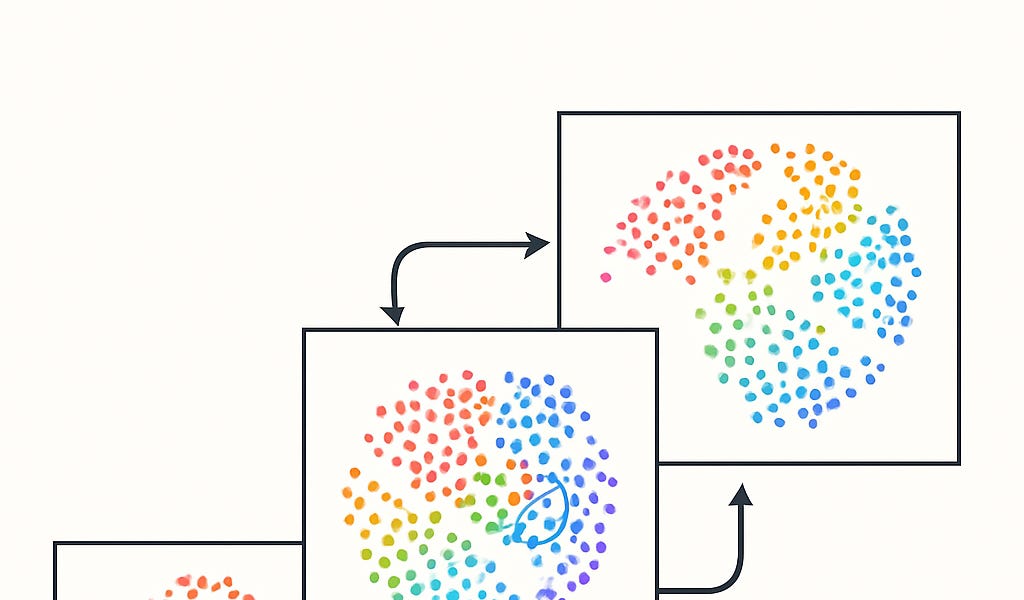
研究者发现大型语言模型在学习过程中趋向于收敛到一个共享的潜在表征空间,这被称为“柏拉图式表征假设”。这一假设意味着不同模型学习到的是相同的特征,即使模型架构不同。 文章以“墨索里尼或面包”游戏为例解释了这种共享表征的可能性,并通过压缩理论和模型泛化能力进行论证。 更重要的是,基于这一假设,研究者开发了一种名为vec2vec的方法,可以无监督地转换不同模型的嵌入空间,甚至实现了高精度文本嵌入反演。这项技术未来可能应用于解码古代文字(例如线性A)或翻译鲸鱼语言,为跨语言理解和人工智能发展带来新的可能性。
阅读更多
