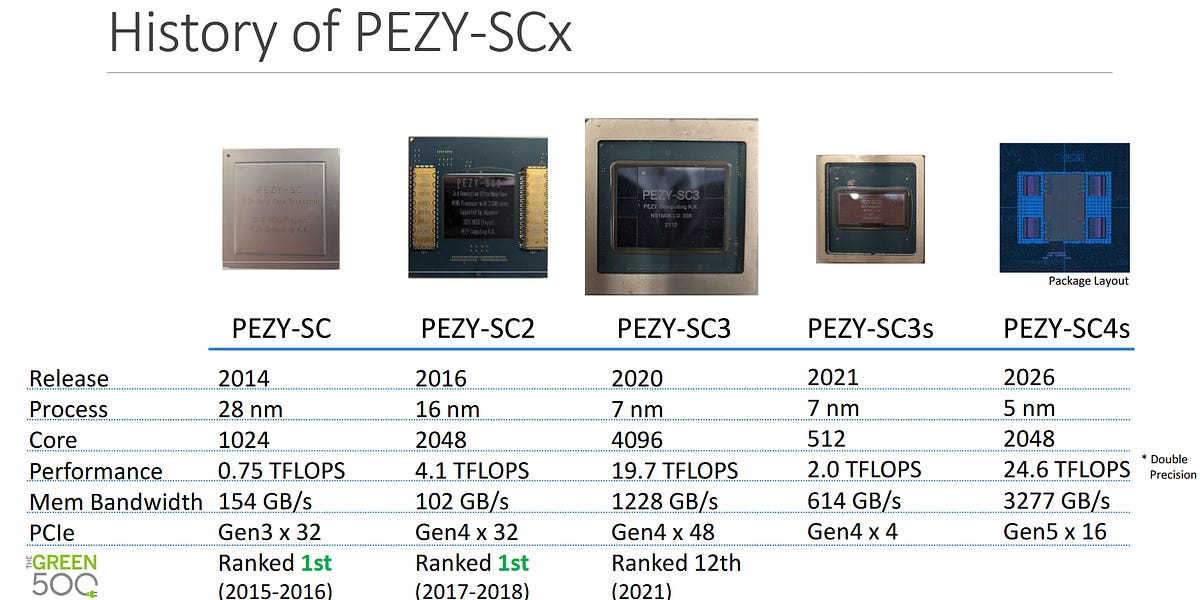
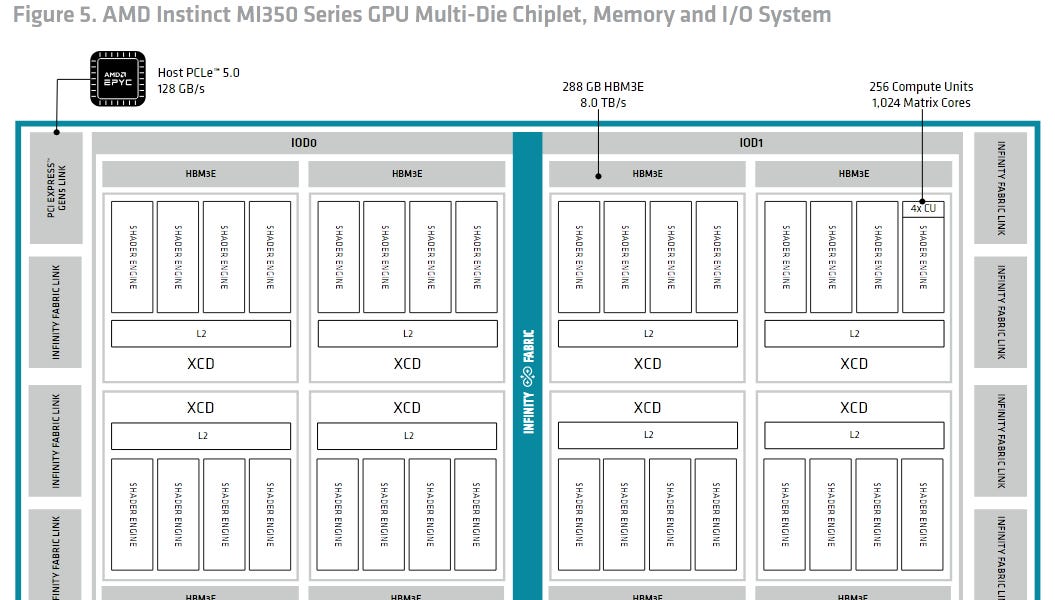
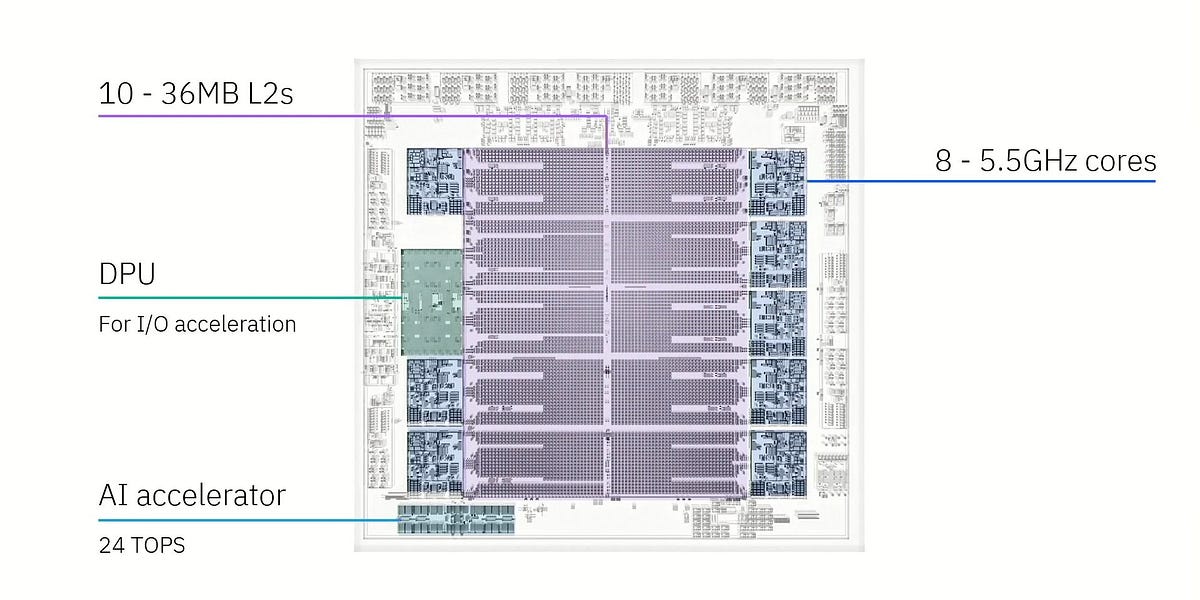
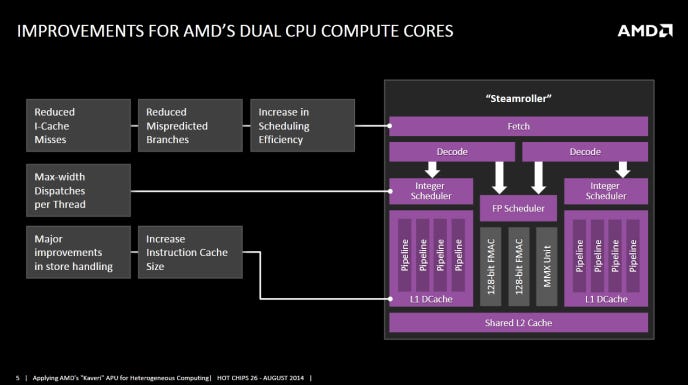
AMD RDNA4架构:效率为王的GPU革新
2025-09-14

AMD最新的RDNA4架构专注于效率提升,而非单纯追求性能巅峰。RX 9000系列显卡搭载RDNA4,在光线追踪和机器学习方面实现了显著的效率提升,同时改进光栅化性能。通过改进的压缩技术、更快的媒体引擎(支持H.264、H.265和AV1编码解码,并降低延迟)、以及增强的显示引擎(集成Radeon Image Sharpening锐化滤镜),RDNA4在功耗控制和多显示器闲置功耗方面表现出色。此外,RDNA4还通过改进的工作组处理器、更大的L2缓存以及优化的Infinity Fabric架构,进一步提升了性能和效率。总而言之,RDNA4代表了AMD在GPU架构设计上的一个重要飞跃,它将效率放在首位,为游戏玩家和专业用户带来更均衡、更节能的体验。
阅读更多
硬件
RDNA4