我的微调模型击败了 OpenAI 的 GPT-4
2024-07-01
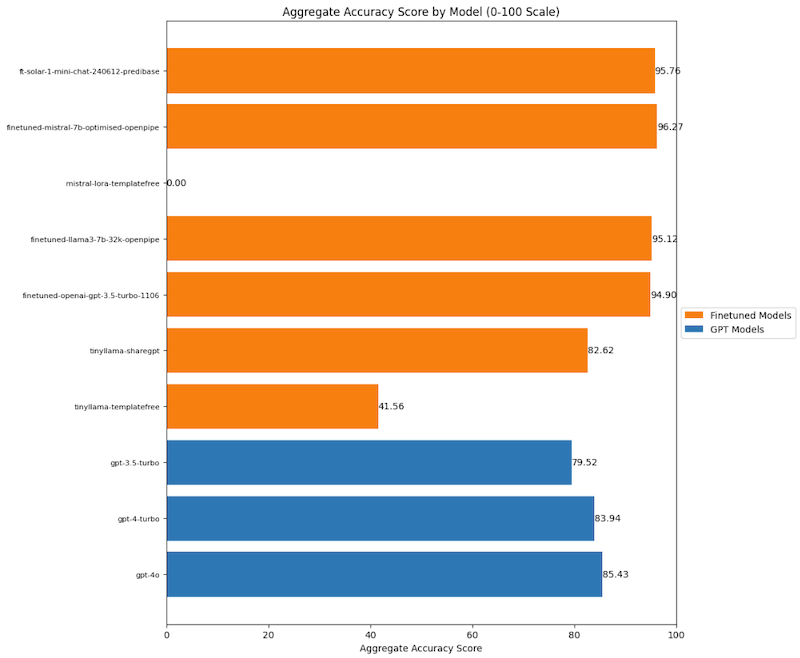
文章详细介绍了作者如何微调 Mistral、Llama3 和 Solar 等大型语言模型,并将其用于从新闻稿中提取结构化数据。作者比较了微调模型与 OpenAI GPT 模型的性能,发现在准确性方面,微调模型优于 GPT 模型,特别是在省份、目标群体和事件类型等方面的识别上。作者还分享了微调和评估模型过程中的经验和教训,以及对未来改进方向的展望。
阅读更多
60
未分类
结构化数据提取