LearnLM团队致谢:大型语言模型背后的功臣
2025-09-19

Google Research LearnLM团队发布文章,对参与项目研发的人员表达感谢。文章列出了众多贡献者姓名,涵盖了从研究员到执行主管等多个角色,体现了团队协作的成功经验。LearnLM项目取得的进展,离不开这些成员的共同努力。
阅读更多
Google Research LearnLM团队发布文章,对参与项目研发的人员表达感谢。文章列出了众多贡献者姓名,涵盖了从研究员到执行主管等多个角色,体现了团队协作的成功经验。LearnLM项目取得的进展,离不开这些成员的共同努力。
阅读更多
Gemma 项目成功离不开 Gemma 和 Google Privacy 团队的通力合作。本文特别感谢 Peter Kairouz、Brendan McMahan 和 Dan Ramage 提供的博客反馈,Mark Simborg 和 Kimberly Schwede 提供的可视化帮助,以及 Google 各团队在算法设计、基础设施实施和生产维护方面提供的支持。文中还列出了对项目直接贡献的 20 位成员名单。
阅读更多
研究人员通过迭代式数据标注,提升了大型语言模型(LLM)的性能。实验使用了两种不同规模的LLM(Gemini Nano-1和Nano-2)以及两个不同复杂度的任务。初始数据为约10万个众包标注,存在严重的类别不平衡问题。通过多次迭代的专家数据筛选和模型微调,模型性能得到显著提升,最终在低复杂度任务上达到约40%的正样本比例,Kappa系数达到0.81,在高复杂度任务上达到0.78,接近专家水平。这表明,高质量的数据标注对提升LLM性能至关重要。
阅读更多
地震预警系统的一个最大挑战在于实时估计地震震级。震级决定了震动波及范围和预警人群。低估震级可能导致漏报,高估则可能引发公众对预警系统的信任危机。如何在速度和精度之间取得平衡是关键。初期数据有限,但延迟预警会减少预警时间。过去三年,我们持续改进震级估算,中位绝对误差已从0.50下降至0.25,精度与传统地震网络相当,甚至部分超越。
阅读更多
现代信息检索依赖于神经嵌入模型,但多向量模型虽然精度高,却因计算复杂度高而效率低下。研究人员提出了一种名为MUVERA的新算法,通过构建固定维编码(FDE),将复杂的多向量检索转化为简单的单向量最大内积搜索(MIPS),从而在不牺牲精度的前提下显著提高效率。该算法的开源实现已发布在GitHub上。
阅读更多
谷歌的Veo视频生成模型取得了重大突破,其第三代版本能够通过微调在各种多模态任务中表现出色,尤其是在新视角合成方面。该模型利用数百万个高质量3D合成资产数据集进行训练,可以将产品图像转换为一致的360°视频。令人印象深刻的是,Veo能够有效地泛化到不同的产品类别,如家具、服装和电子产品等,并准确捕捉复杂的照明和材质交互,这是前两代模型难以实现的。
阅读更多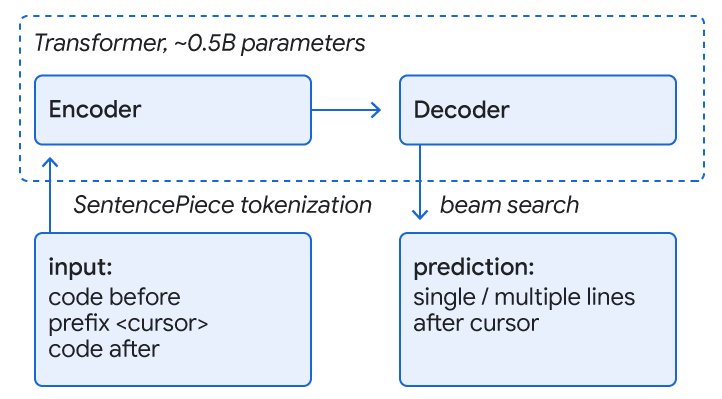
谷歌的研究人员开发了一种创新的基于Transformer的混合语义机器学习代码补全系统,将机器学习(ML)与基于规则的语义引擎(SE)相结合,显著提升了开发效率。该系统通过三种方式整合ML和SE:1)利用ML重新排序SE的单token建议;2)使用ML进行单行和多行补全,并用SE检查正确性;3)利用ML对单token语义建议进行单行和多行续写。在1万多名谷歌内部开发者参与的为期三个月的测试中,单行ML补全使编码迭代时间减少了6%。目前,超过3%的新代码是由ML补全建议生成的。该系统支持八种编程语言,并通过语义检查确保代码的正确性,极大提升了开发者的信任度和工作效率。
阅读更多
一项研究发现,OpenAI的Whisper语音识别模型的内部表征与人类大脑在自然对话中处理语言的神经活动惊人地一致。研究人员通过比较Whisper模型的嵌入与大脑不同区域(如额下回IFG和颞上回STG)的神经活动,发现模型的语言嵌入在语音产生过程中先于语音嵌入达到峰值,而在语音理解过程中则相反。这表明Whisper模型,即使没有考虑大脑的语言处理机制,也能捕捉到语言处理的关键神经机制,并揭示了大脑语言处理中存在“软分层”结构:高级区域如IFG优先处理语义和句法信息,但也处理低级听觉特征;低级区域如STG优先处理声学和语音信息,但也处理词级信息。
阅读更多
这篇论文的成功离不开Asaf Aharoni、Avinatan Hassidim和Danny Vainstein等人的密切合作。此外,研究团队还要感谢YaGuang Li、Blake Hechtman等数十位来自Google Research、Google Deepmind和Google Search团队的成员提供的宝贵意见、支持和帮助,他们的辛勤付出对研究成果的最终完成至关重要。
阅读更多
这篇论文致谢了来自谷歌研究院、谷歌DeepMind和谷歌云AI团队的大量研究人员,以及来自弗莱明倡议、伦敦帝国理工学院、休斯顿卫理公会医院、Sequome和斯坦福大学的合作者。它强调了这项研究的协作性质,并感谢了许多为该项目提供技术和专业反馈的科学家、以及谷歌内部为该项目提供支持的团队成员,包括产品、工程和管理团队。这份长长的感谢名单体现了大型AI项目背后的庞大团队努力。
阅读更多
谷歌软件工程师Joshua Bloch爆料,一个潜伏了近二十年的二分查找算法bug,竟然出现在JDK和Jon Bentley的《编程珠玑》中!这个bug源于`int mid = (low + high) / 2;`这行代码,当`low`和`high`之和超过最大正整数时会发生整数溢出,导致数组越界。这个bug在数据量巨大的情况下才会暴露,在如今的大数据时代尤为致命。文章还讨论了多种修复方法,并强调了即使经过严格测试和证明,代码中仍然可能存在难以发现的bug,告诫程序员要保持谨慎和谦逊。
阅读更多
谷歌的研究人员利用机器学习模型处理卫星图像,创建了高分辨率的数字表面模型和屋顶分割图,从而扩展了谷歌地图平台太阳能API在全球南方的覆盖范围。这项创新克服了传统方法在数据获取和处理上的局限性,为全球12.5亿建筑物提供了太阳能潜力评估数据,加速了全球各地可再生能源的采用。该项目利用卫星数据提高了数据更新频率,并降低了成本,尤其对数据匮乏的地区意义重大。
阅读更多
本文介绍了一种名为Iterative BC-Max的新技术,旨在通过改进内联决策来减小编译后二进制文件的大小。该技术通过解决精心设计的监督学习问题而不是使用不稳定且计算量大的强化学习算法来生成决策策略。与现有的强化学习算法相比,Iterative BC-Max具有多项优势,包括更少的编译器交互、对不可靠奖励信号的鲁棒性,以及只需解决二元分类问题。该技术通过迭代地编译程序语料库和学习新的编译策略,最终实现二进制文件大小的减小。实验结果表明,在搜索应用程序二进制文件上,Iterative BC-Max相比于进化策略基线实现了约1%的大小缩减。
阅读更多
谷歌研究人员提出了一种名为InkSight的模型,可以将手写笔记的照片转换为数字墨水格式,并再现笔画轨迹,无需专用设备。该模型结合了OCR技术和机器学习,通过学习“阅读”识别文字和学习“书写”输出笔画,从而实现更鲁棒的转换,即使在光线条件差或存在遮挡的情况下也能良好工作。该模型将笔记数字化分成三个步骤:OCR提取单词边界框、分别对每个单词进行渲染以及用渲染的笔画替换原始像素表示。这种方法解决了现有方法对专用硬件的依赖以及缺乏配对训练数据的难题,并通过多任务训练设置(包括识别和渲染任务)提高了模型的泛化能力。
阅读更多
本文介绍了PDLP,一种基于一阶方法的大规模线性规划求解器。传统线性规划求解器在处理超大规模问题时,面临内存溢出和硬件挑战。PDLP利用矩阵向量乘法而非矩阵分解,降低了内存需求,更适用于GPU和分布式系统等现代计算技术。PDLP的核心算法是重启的原始对偶混合梯度法(PDHG),并进行了预解、预处理、不可行性检测、自适应重启和自适应步长等改进。PDLP已开源并集成到Google的OR-Tools中,并在数据中心网络流量工程、集装箱运输优化和旅行商问题等方面有广泛应用。
阅读更多
本文介绍了 YouTube Music 如何使用 Transformer 模型改进音乐推荐系统。传统的推荐系统难以理解用户行为的顺序性和上下文关联性,导致推荐结果不精准。YouTube Music 利用 Transformer 模型分析用户的历史行为,例如跳过、喜欢或不喜欢歌曲等,并根据当前场景(如健身、驾驶)调整推荐策略。这种方法有效降低了跳过率,提高了用户听音乐的时间,提升了用户满意度。
阅读更多
StreamVC是一种实时语音转换解决方案,可以保留任何源语音的内容和韵律,同时匹配任何目标语音的音色。与以前的方法不同,StreamVC即使在移动平台上也能从输入信号中以低延迟生成结果波形,使其适用于实时通信场景,如电话和视频会议,并解决了这些场景中的语音匿名化等用例。
阅读更多
本文介绍了谷歌公司提出的一种新的企业安全方法——BeyondCorp。该方法摒弃了传统的基于防火墙的边界安全模型,而是将所有企业应用程序迁移到互联网上,并取消了特权内网的概念。
阅读更多
本文介绍了谷歌内部软件开发工具中人工智能应用的最新进展,并预测了未来五年该领域的趋势。谷歌内部团队成功将人工智能应用于代码补全、代码审查意见解决和代码粘贴适配等方面,显著提高了软件工程师的生产力。未来,人工智能将在软件测试、代码理解和代码维护等更广泛的领域发挥作用,自然语言也将成为软件工程任务和信息获取的主要接口。
阅读更多
文章介绍了谷歌运营研究团队开发的航运网络设计 API,该 API 采用新的解决方案,能够更好地解决货船路线优化问题,在规模、速度和效率方面超越以往的尝试。文章详细介绍了线性航运网络设计和调度问题(LSNDSP)的三大组成部分:网络设计、网络调度和集装箱路由,以及解决这些问题的两种基本方法:双列生成和 CP-SAT。文章还介绍了为提高可扩展性而采用的启发式策略,包括大邻域搜索和可变邻域搜索,并通过与 LINERLIB 基准测试的比较,展示了该解决方案在集装箱吞吐量、船舶数量和利润率方面的显著改进。
阅读更多
谷歌研究院推出了VideoPrism,这是一个用于视频理解的基础视觉编码器。VideoPrism 旨在处理各种视频理解任务,包括分类、定位、检索、字幕和问答。VideoPrism 在包含 3600 万个高质量视频文本对和 5.82 亿个带噪声或机器生成文本的视频片段的大规模多样化数据集上进行预训练。VideoPrism 很容易适应新的视频理解挑战,并使用单个冻结模型实现了最先进的性能。
阅读更多
谷歌宣布在搜索中添加一项新功能,允许英语学习者练习口语。这项新功能利用谷歌的语音识别技术,让学习者可以对着手机或电脑大声朗读文本,并获得即时反馈。反馈包括对发音、流利性和完整性的评估。该功能还提供了一些练习活动,例如重复句子和回答问题。谷歌表示,这项功能旨在为英语学习者提供一种在真实场景中练习口语的便捷方式。
阅读更多
该网站是谷歌研究院博客文章,介绍了如何使用流网络算法解决带权无向图的最小割问题。文中详细介绍了算法的步骤,并给出了一个示例来说明算法的运作方式。
阅读更多