Mirage Persistent Kernel: Kompilierung von LLMs in einen einzigen Megakernel für blitzschnelle Inferenz
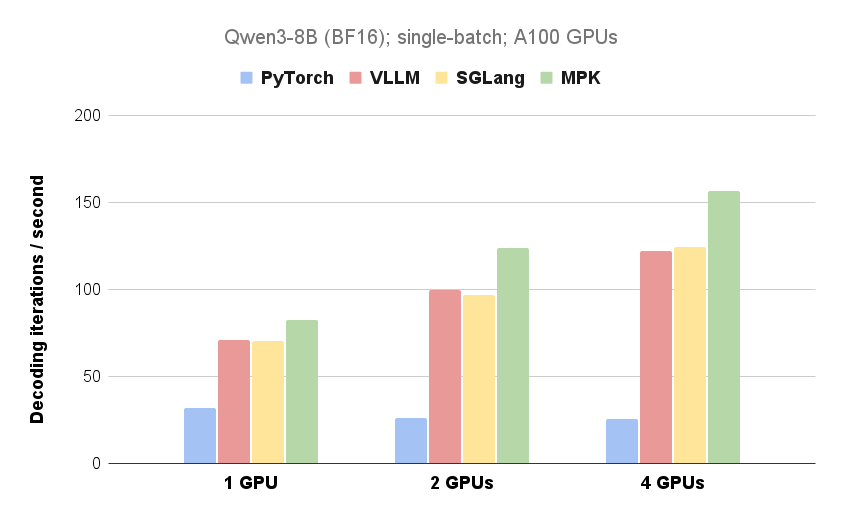
Forscher der CMU, UW, Berkeley, NVIDIA und Tsinghua haben Mirage Persistent Kernel (MPK) entwickelt, ein Compiler- und Laufzeitsystem, das die Inferenz großer Sprachmodelle (LLMs) auf mehreren GPUs automatisch in einen Hochleistungs-Megakernel umwandelt. Durch die Fusion aller Berechnungen und Kommunikation in einen einzigen Kernel eliminiert MPK den Kernel-Start-Overhead, überlappt Berechnungen und Kommunikation und reduziert die Latenz der LLM-Inferenz erheblich. Experimente zeigen substantielle Leistungsverbesserungen bei Einzel- und Mehr-GPU-Konfigurationen, wobei die Vorteile bei Mehr-GPU-Systemen stärker ausgeprägt sind. Zukünftige Arbeiten konzentrieren sich auf die Erweiterung von MPK zur Unterstützung von GPU-Architekturen der nächsten Generation und zur Behandlung dynamischer Workloads.