LLMs: Der unerwartete Erfolg des Dokumentenrankings
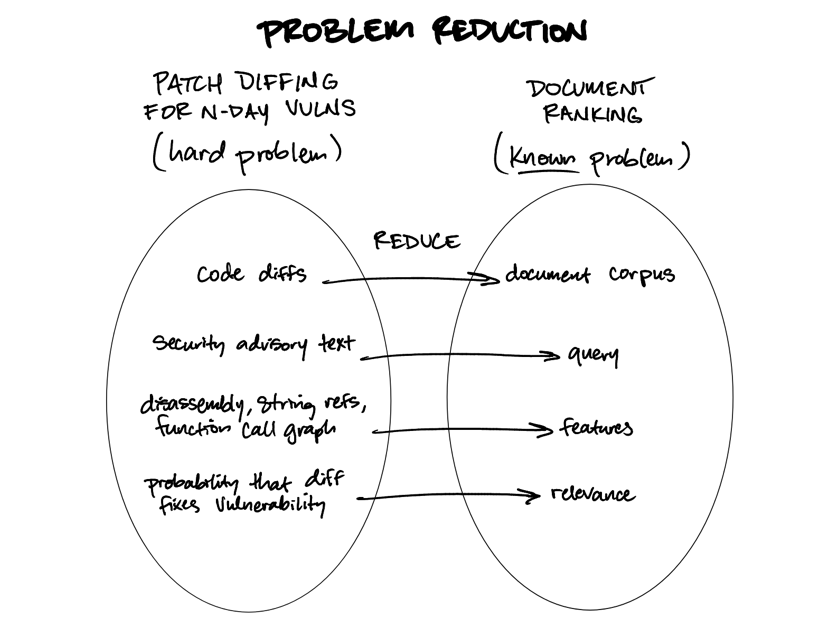
Dieser Artikel argumentiert, dass Large Language Models (LLMs) effektiv für das listweise Dokumentenranking verwendet werden können und dass überraschenderweise einige komplexe Probleme gelöst werden können, indem sie in Dokumentenranking-Probleme umgewandelt werden. Der Autor demonstriert dies anhand der Verwendung von Patch-Differenzen zur Lokalisierung von N-Day-Schwachstellen. Durch die Umformulierung des Problems als Ranking von Differenzen (Dokumente) nach ihrer Relevanz für eine Sicherheitswarnung (Abfrage) können LLMs effizient die spezifische Funktion identifizieren, die eine Schwachstelle behebt. Diese Technik wurde auf mehreren Sicherheitskonferenzen validiert und kann auf andere Sicherheitsprobleme angewendet werden, wie z. B. die Auswahl und Priorisierung von Fuzzing-Zielen. Zukünftige Verbesserungen umfassen die Analyse der Rangfolgeergebnisse und die Generierung verifizierbarer Beweise, wie z. B. die automatische Generierung testbarer Proof-of-Concept-Exploits.