Optimierte FP32-Matrixmultiplikation auf AMD RDNA3-GPU: Übertrifft rocBLAS um 60 %
2025-03-28
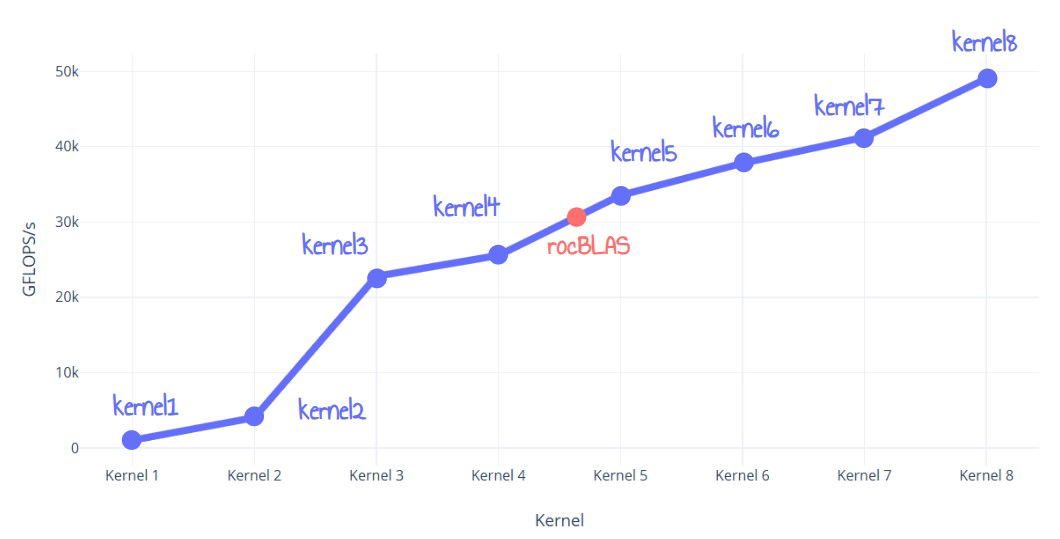
Dieser Beitrag beschreibt die Optimierung einer FP32-Matrixmultiplikation für AMD RDNA3-GPUs, die rocBLAS um 60 % übertrifft. Der Autor verfeinert iterativ acht Kernels, beginnend mit einer naiven Implementierung und fortschreitend zu ISA-Ebene-Optimierungen. Techniken umfassen LDS-Tiling, Register-Tiling, Global Memory Double Buffering, LDS-Auslastungsoptimierung und schließlich ISA-Ebene-VALU-Optimierung und Loop Unrolling. Der finale Kernel übertrifft rocBLAS und erreicht fast 50 TFLOPS.
Entwicklung