Der Mythos der Polynome hohen Grades in der Regression
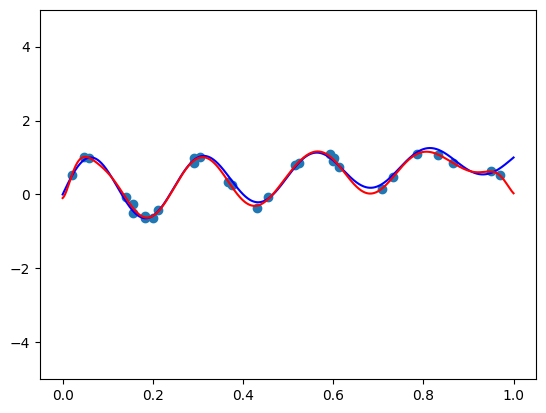
Die weit verbreitete Annahme, dass Polynome hohen Grades im maschinellen Lernen anfällig für Overfitting sind und schwer zu kontrollieren sind, wird in diesem Artikel in Frage gestellt. Der Autor argumentiert, dass das Problem nicht die Polynome hohen Grades selbst sind, sondern die Verwendung ungeeigneter Basisfunktionen, wie der Standardbasis. Experimente, die die Standardbasis, Chebyshev-Basis und Legendre-Basis mit der Bernstein-Basis beim Anpassen verrauschter Daten vergleichen, zeigen, dass die Bernstein-Basis mit ihren Koeffizienten, die die gleichen „Einheiten“ haben und leicht zu regularisieren sind, Overfitting effektiv vermeidet. Sogar Polynome hohen Grades liefern mit der Bernstein-Basis exzellente Anpassungen, wobei nur eine minimale Feinabstimmung der Hyperparameter erforderlich ist.