Ausrichtung von Polynommerkmalen mit der Datenverteilung: Das Problem der Aufmerksamkeitsausrichtung im ML
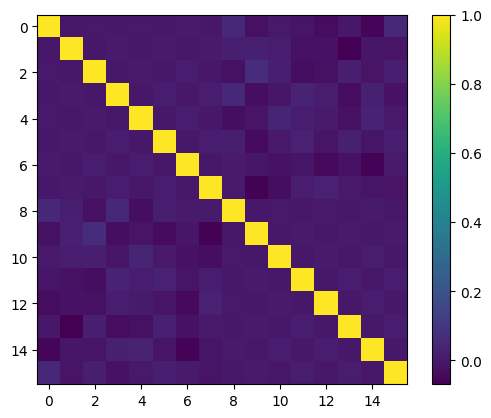
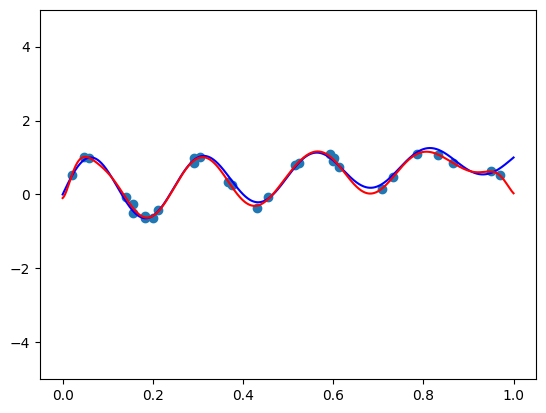
Dieser Beitrag untersucht die Ausrichtung von Polynommerkmalen mit der Datenverteilung, um die Leistung des maschinellen Lernmodells zu verbessern. Orthogonale Basen erzeugen informative Merkmale, wenn die Daten gleichmäßig verteilt sind, aber das ist bei realen Daten nicht der Fall. Zwei Ansätze werden vorgestellt: ein Mapping-Trick, der die Daten in eine gleichmäßige Verteilung transformiert, bevor eine orthogonale Basis angewendet wird; und die Multiplikation mit einer sorgfältig ausgewählten Funktion, um die Gewichtsfunktion der orthogonalen Basis so anzupassen, dass sie mit der Datenverteilung übereinstimmt. Der erste Ansatz ist praktischer und mit dem QuantileTransformer von Scikit-Learn erreichbar. Der zweite ist komplexer und erfordert ein tieferes mathematisches Verständnis und Feinabstimmung. Experimente mit dem California Housing Dataset zeigen, dass die nahezu orthogonalen Merkmale des ersten Ansatzes die traditionelle Min-Max-Skalierung bei der linearen Regression übertreffen.
Mehr lesen