OpenAI veröffentlicht gpt-oss: Leistungsstarke, lokal ausführbare Open-Weight LLMs
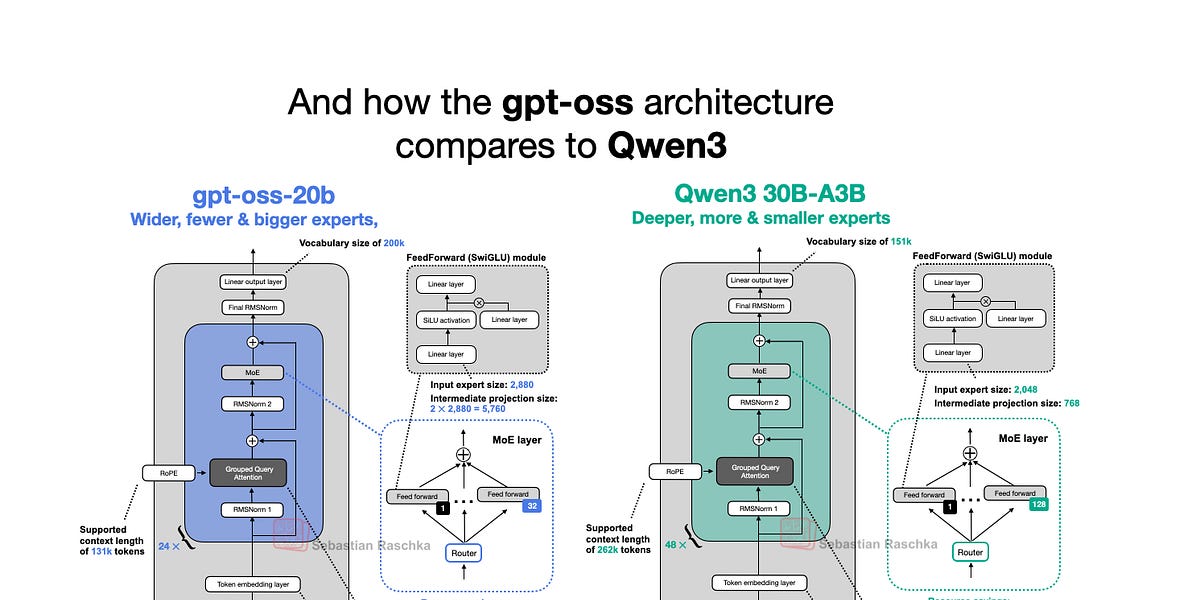
OpenAI hat diese Woche seine neuen Open-Weight LLMs veröffentlicht: gpt-oss-120b und gpt-oss-20b, die ersten Open-Weight-Modelle seit GPT-2 im Jahr 2019. Überraschenderweise können sie dank cleverer Optimierungen lokal ausgeführt werden. Dieser Artikel untersucht die Architektur des gpt-oss-Modells und vergleicht sie mit Modellen wie GPT-2 und Qwen3. Er hebt einzigartige architektonische Entscheidungen hervor, wie z. B. Mixture-of-Experts (MoE), Grouped Query Attention (GQA) und Sliding-Window-Attention. Obwohl Benchmarks zeigen, dass gpt-oss in einigen Bereichen mit proprietären Modellen vergleichbare Leistungen erzielt, machen seine lokale Ausführungsfähigkeit und sein Open-Source-Charakter ihn zu einer wertvollen Ressource für Forschung und Anwendungen.
Mehr lesen
