Jenseits von BPE: Die Zukunft der Tokenisierung in großen Sprachmodellen
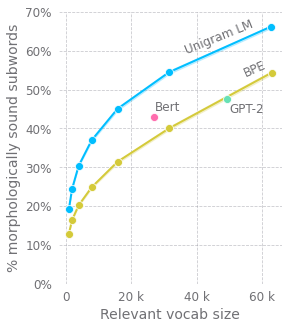
Dieser Artikel untersucht Verbesserungen bei Tokenisierungsmethoden in großen, vortrainierten Sprachmodellen. Der Autor hinterfragt die gängige Byte-Pair-Encoding (BPE)-Methode und hebt deren Schwächen bei der Behandlung von Subwörtern am Wortanfang und im Wortinneren hervor. Es werden Alternativen vorgeschlagen, wie z. B. das Hinzufügen einer neuen Wortmaske. Darüber hinaus argumentiert der Autor gegen die Verwendung von Komprimierungsalgorithmen zur Vorverarbeitung von Eingaben und befürwortet stattdessen die Charakter-basierte Sprachmodellierung, wobei Parallelen zu rekurrenten neuronalen Netzen (RNNs) und tieferen Self-Attention-Modellen gezogen werden. Die quadratische Komplexität des Aufmerksamkeitsmechanismus stellt jedoch eine Herausforderung dar. Der Autor schlägt einen Ansatz basierend auf einer Baumstruktur vor, der gefensterte Subsequenzen und hierarchische Aufmerksamkeit nutzt, um die Rechenkomplexität zu reduzieren und gleichzeitig die Sprachstruktur besser zu erfassen.
Mehr lesen