Cerebras bringt blitzschnelle KI-Coding-Pläne heraus: Pro & Max
2025-08-02

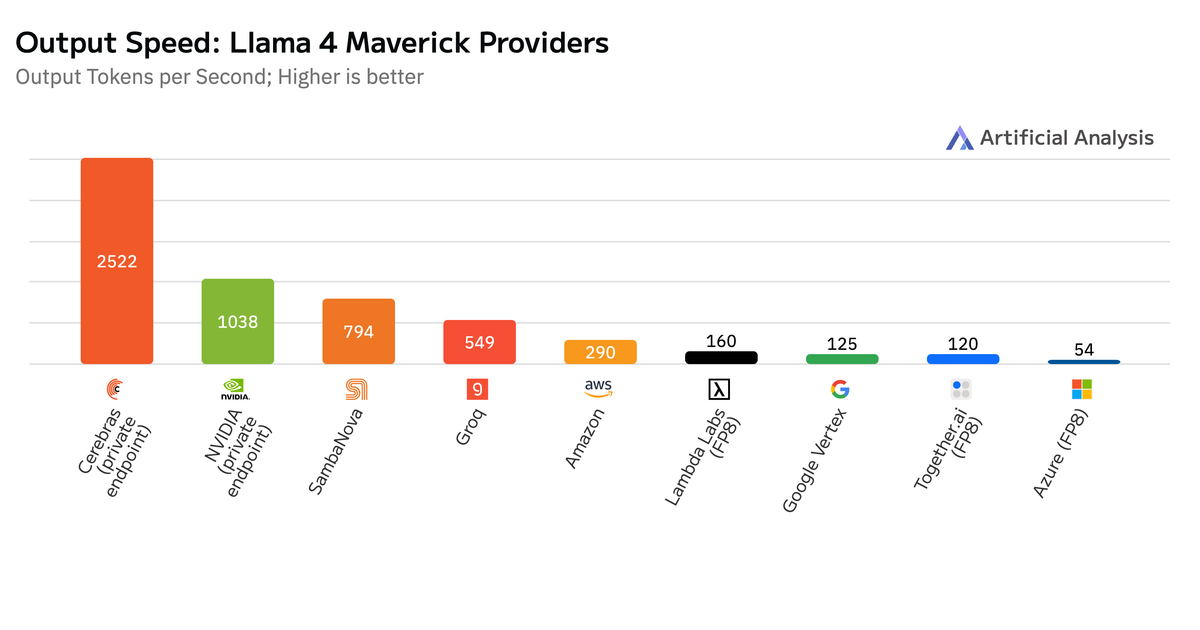
Cerebras präsentiert zwei neue KI-Coding-Pläne: Code Pro (50 $ pro Monat) und Code Max (200 $ pro Monat), beide angetrieben von Alibabas Qwen3-Coder, einem führenden Open-Weight-Coding-Modell. Mit Geschwindigkeiten von bis zu 2000 Tokens pro Sekunde, einem Kontextfenster von 131.000 Tokens und ohne proprietäre IDE-Bindung oder wöchentliche Limits bietet es eine sofortige Codegenerierung. Benutzer können es in ihre bevorzugten KI-IDEs integrieren, für einen nahtlosen Workflow. Code Pro ist ideal für einzelne Entwickler und kleinere Projekte, während Code Max die Anforderungen von Vollzeitentwicklern mit hohem Volumen erfüllt.
Mehr lesen
Entwicklung