Das Geheimnis von Word2Vec: Traditionelle und neuronale Methoden im Vergleich
2025-02-17
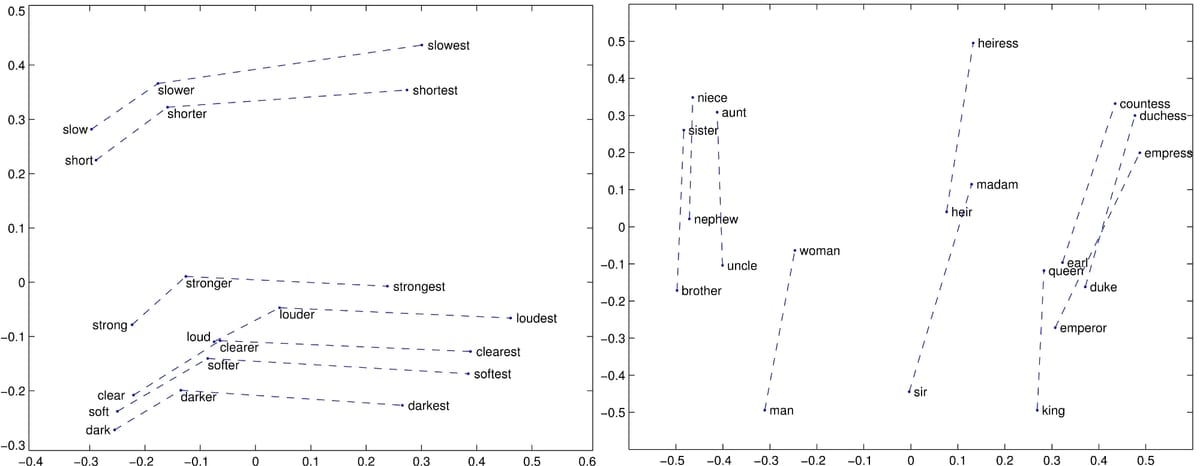
Dieser Blogbeitrag untersucht die Faktoren, die zum Erfolg von Word2Vec beitragen, und seine Beziehung zu traditionellen Wort-Embedding-Modellen. Durch den Vergleich von Modellen wie GloVe, SVD, Skip-gram with Negative Sampling (SGNS) und PPMI zeigt der Autor, dass das Tuning von Hyperparametern oft wichtiger ist als die Wahl des Algorithmus. Die Forschung demonstriert, dass traditionelle distributional semantische Modelle (DSMs) mit geeigneter Vor- und Nachbearbeitung eine mit neuronalen Netzwerkmodellen vergleichbare Leistung erzielen können. Der Artikel hebt die Vorteile der Kombination traditioneller und neuronaler Methoden hervor und bietet eine neue Perspektive auf das Lernen von Wort-Embeddings.
Mehr lesen