Anthropic 的 Claude AI:多智能体系统赋能的网络搜索
2025-06-21

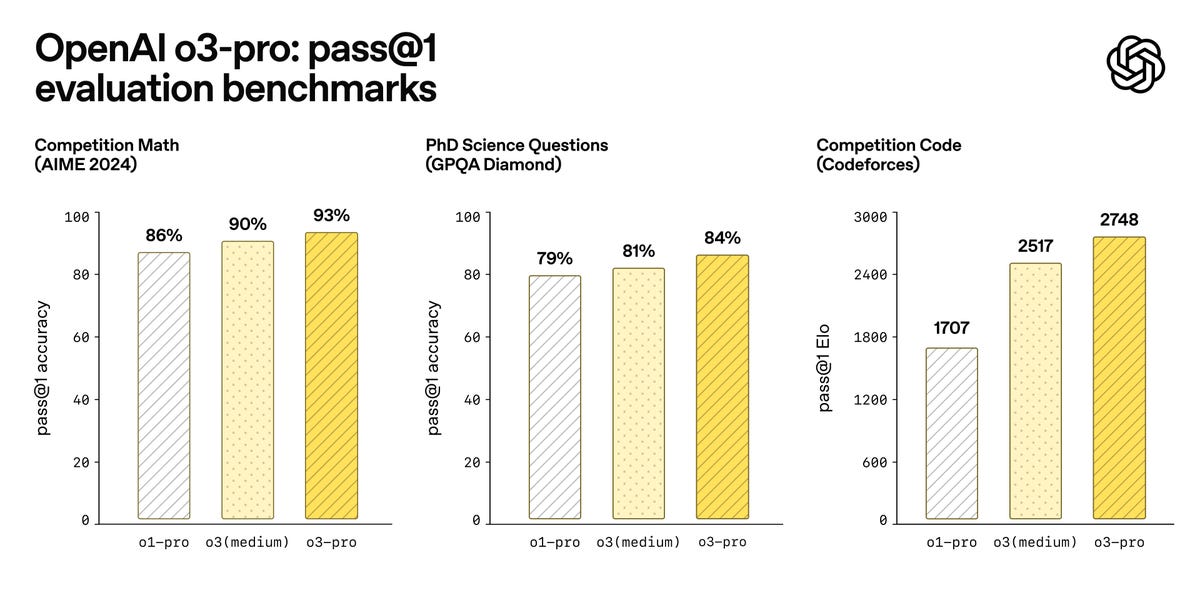
Anthropic公司在其大型语言模型Claude中引入了新的研究功能,该功能利用多智能体系统在网络、Google Workspace以及其他集成工具上进行复杂任务的搜索。文章详细介绍了该系统的架构、工具设计和提示工程,以及如何通过多代理协作、并行搜索和动态信息检索来提升搜索效率。多智能体系统虽然消耗更多token,但在处理需要广泛搜索和并行处理的任务时,其性能显著优于单智能体系统。该系统在内部评估中表现出色,尤其在需要同时探索多个方向的广度优先查询方面。
AI