AI模型合金:性能提升的秘密武器
2025-07-21

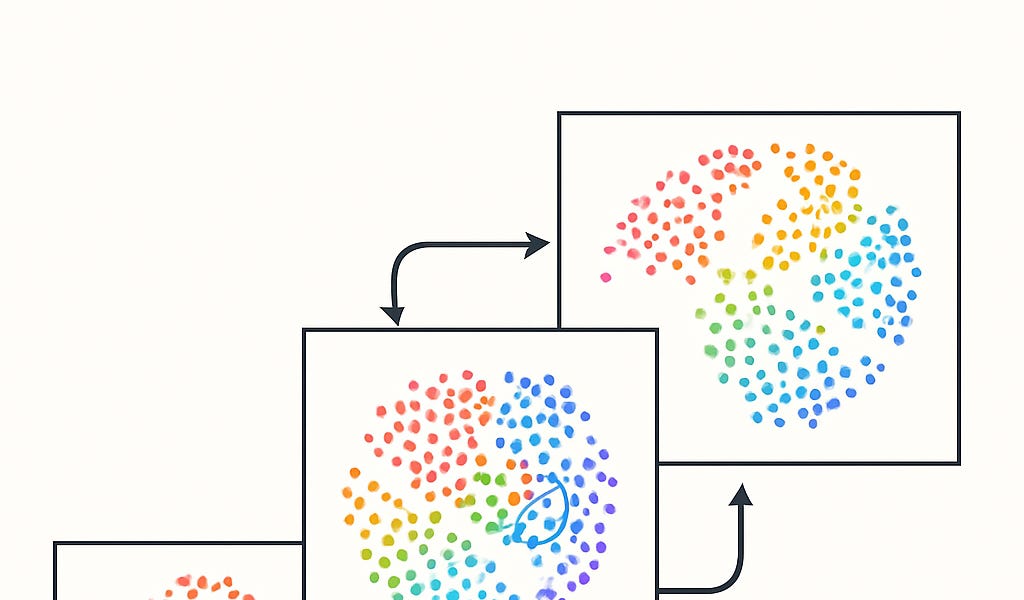
XBOW团队通过一种巧妙的方法——“模型合金”,显著提升了其漏洞检测代理的性能。该方法将不同LLM(如Google Gemini和Anthropic Sonnet)的优势结合,在一个单一对话线程中交替使用,从而突破了单个模型的局限。实验结果表明,这种“合金”策略能够将成功率提升至55%以上,远超单个模型的表现。这项技术并非局限于网络安全领域,对各种需要在庞大搜索空间中寻找解决方案的AI代理任务都具有借鉴意义。
(xbow.com)
AI
模型融合