NetBox发布全新网络发现代理,助力快速构建网络拓扑
2024-12-23

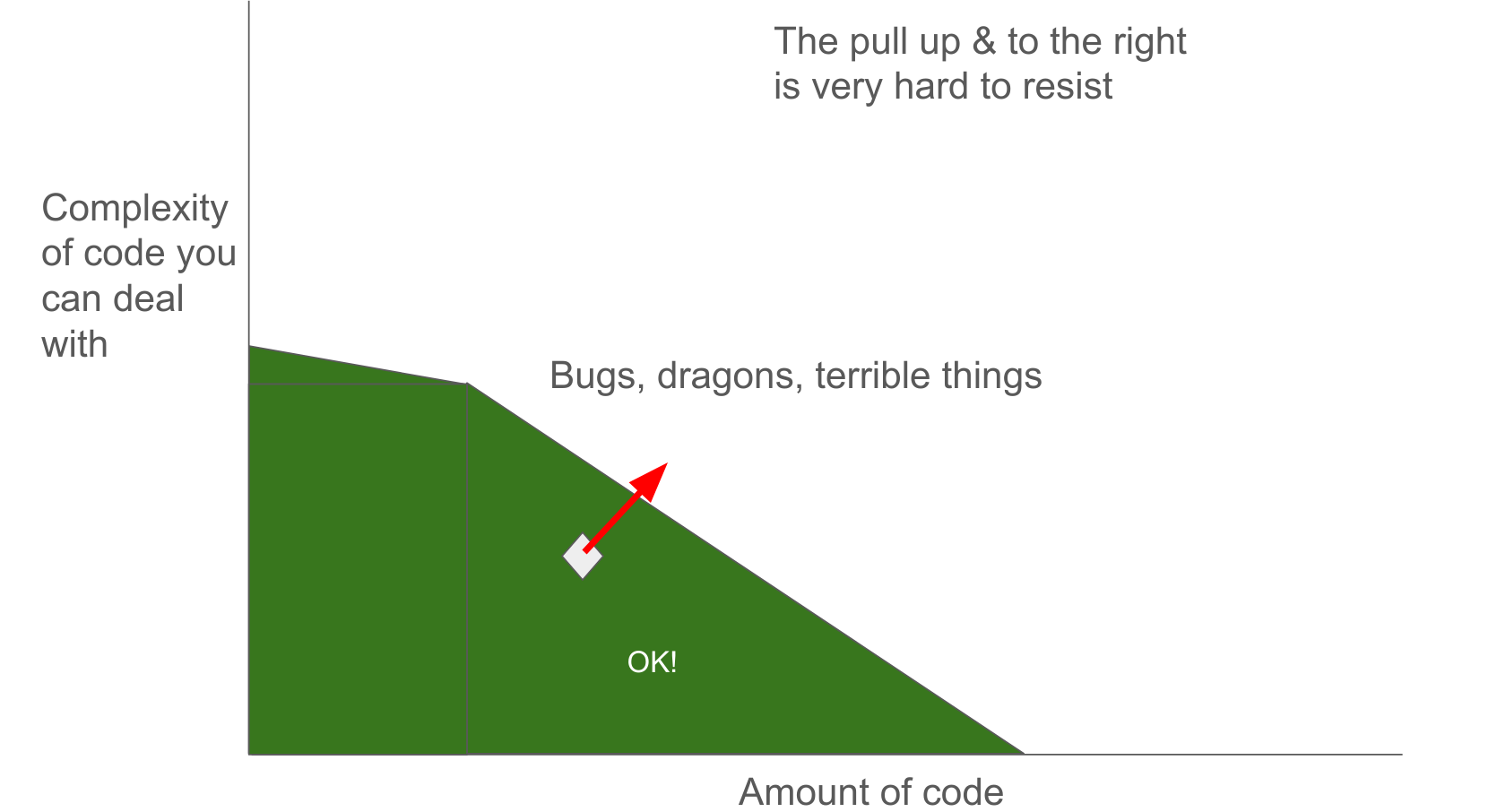
NetBox Labs近日发布了NetBox Discovery代理的公开预览版。该代理是一个完全开源的工具,可以快速简便地发现网络和设备,并将信息导入NetBox,从而加速构建以NetBox为核心的网络真相来源。它支持基于代理的架构,适合复杂的网络环境,并能与NetBox Assurance协同工作,帮助用户检测和修复网络漂移。目前支持两种发现模式:网络发现和设备发现,并与Diode数据摄取引擎集成。