SIMD-Funktionen: Das Versprechen und die Gefahren der automatischen Vektorisierung durch den Compiler
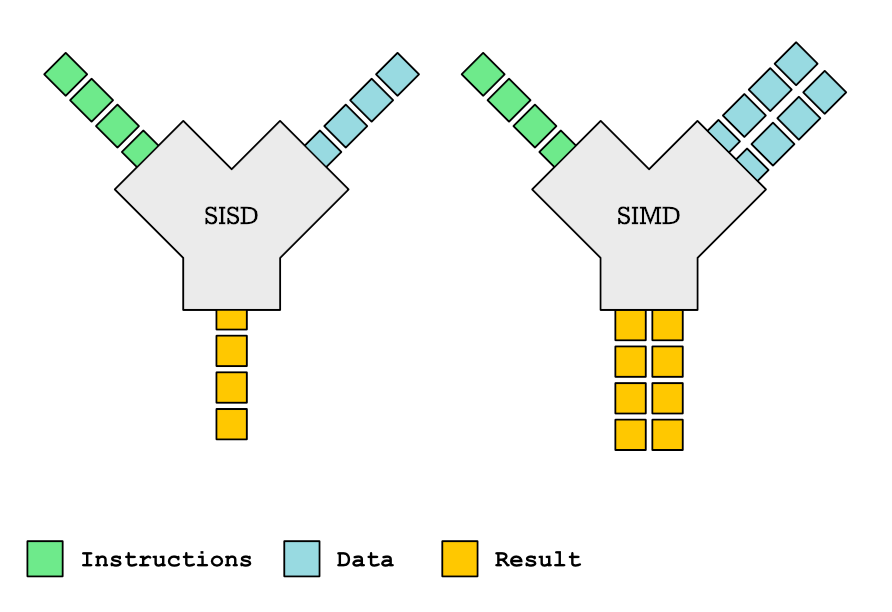
Dieser Beitrag untersucht die Komplexität von SIMD-Funktionen und ihre Rolle bei der automatischen Vektorisierung durch den Compiler. SIMD-Funktionen, die mehrere Daten gleichzeitig verarbeiten können, bieten erhebliche Performance-Verbesserungen. Allerdings ist die Compiler-Unterstützung für SIMD-Funktionen uneinheitlich, und der generierte vektorisierte Code kann überraschend ineffizient sein. Der Artikel beschreibt detailliert, wie man SIMD-Funktionen mit OpenMP-Pragmas und compilerspezifischen Attributen deklariert und definiert, wobei der Einfluss verschiedener Parametertypen (variabel, uniform, linear) auf die Effizienz der Vektorisierung analysiert wird. Er behandelt auch die Bereitstellung benutzerdefinierter vektorisierter Implementierungen mithilfe von Intrinsics, die Behandlung von Funktions-Inlining und die Bewältigung von Compiler-Eigenheiten. Obwohl sie Performance-Gewinne versprechen, stellt die praktische Anwendung von SIMD-Funktionen erhebliche Herausforderungen dar.
Mehr lesen

