Ein pragmatischer Blick eines Senior Data Scientists auf generative KI

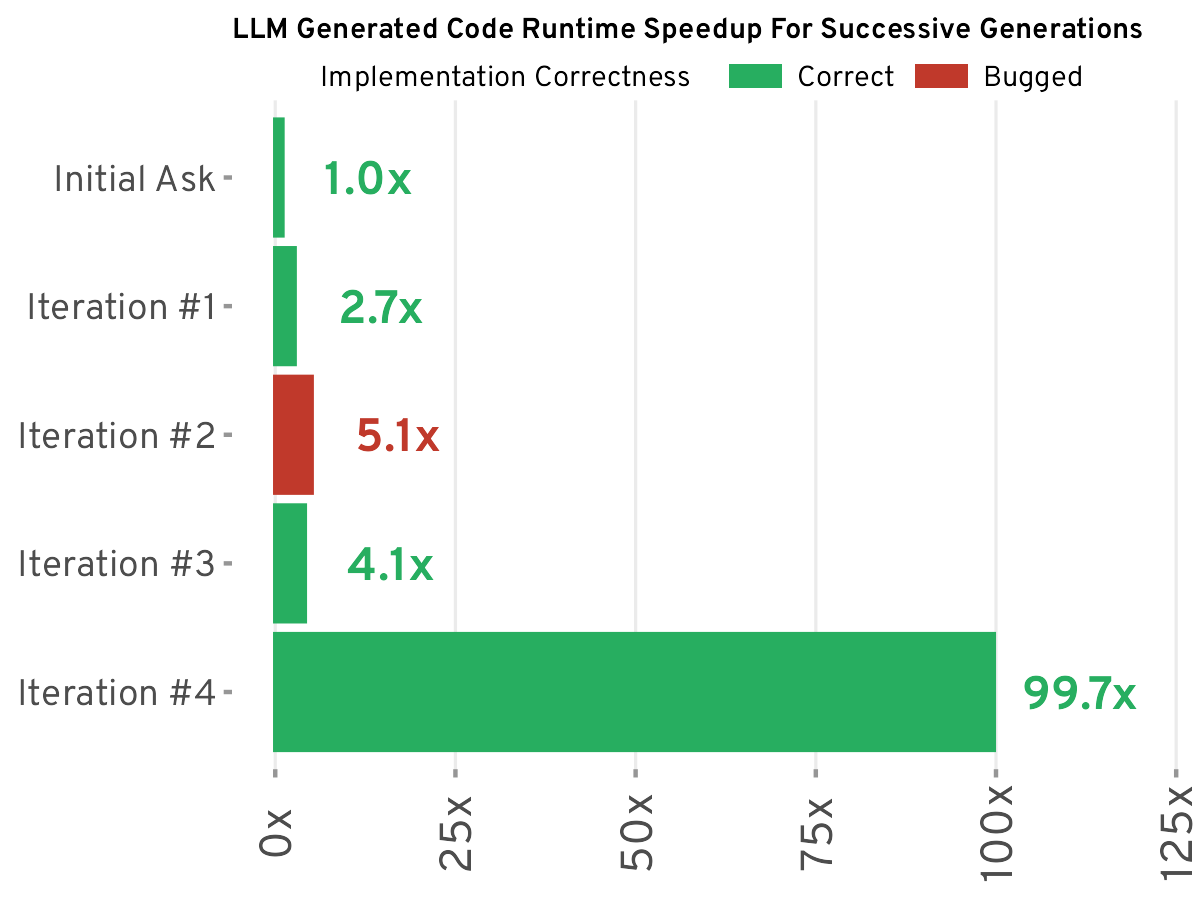
Ein Senior Data Scientist bei BuzzFeed teilt seinen pragmatischen Ansatz zur Nutzung großer Sprachmodelle (LLMs). Er sieht LLMs nicht als Allheilmittel, sondern als Werkzeug zur Effizienzsteigerung und betont die Bedeutung von Prompt Engineering. Der Artikel beschreibt die erfolgreiche Anwendung von LLMs für Aufgaben wie Datenkategorisierung, Textzusammenfassung und Codegenerierung, räumt aber auch deren Grenzen ein, insbesondere in komplexen Data-Science-Szenarien, wo Genauigkeit und Effizienz beeinträchtigt sein können. Er argumentiert, dass LLMs keine Allzwecklösung sind, aber bei kluger Anwendung die Produktivität deutlich steigern können. Der Schlüssel liegt in der Auswahl des richtigen Werkzeugs für die jeweilige Aufgabe.
Mehr lesen