Deep Code Bench: Ein neuer Benchmark-Datensatz für die Code-Retrieval
2025-09-11

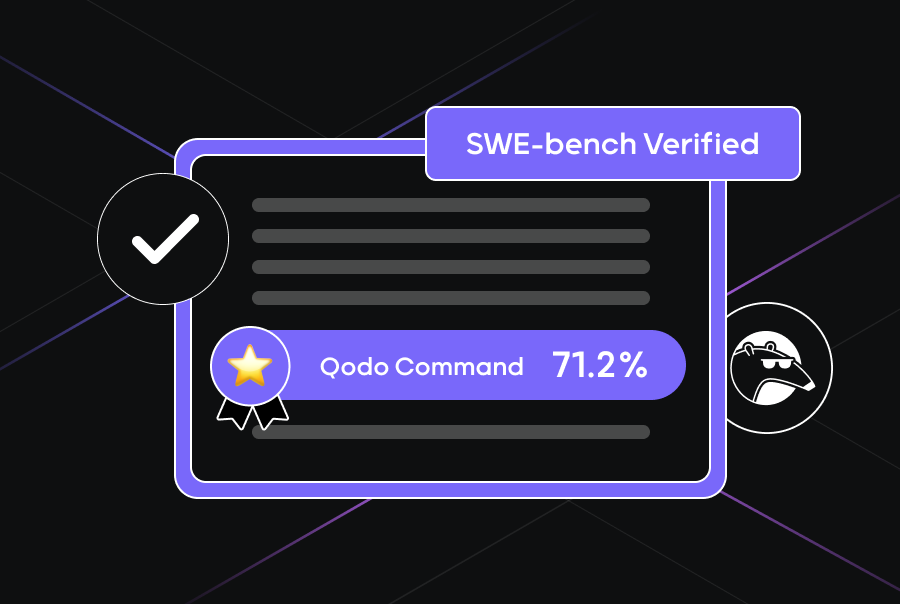
Qodo hat Deep Code Bench veröffentlicht, einen neuen Benchmark-Datensatz mit realen Fragen aus großen, komplexen Code-Repositories. Im Gegensatz zu bestehenden Benchmarks erfordern diese Fragen das Abrufen von Informationen über mehrere Dateien hinweg, was reale Entwicklerszenarien widerspiegelt. Der Datensatz, der mithilfe von LLMs aus Pull-Request-Daten generiert wurde, bietet eine robuste Bewertung von Code-Retrieval-Systemen. Qodos Deep-Research-Agent übertrifft andere in Bezug auf den Fakten-Recall und erreicht etwa 76 % Genauigkeit.
Mehr lesen
Entwicklung
Benchmark-Datensatz