Waymo自动驾驶事故分析:人类才是事故的主要元凶?
2025-03-26

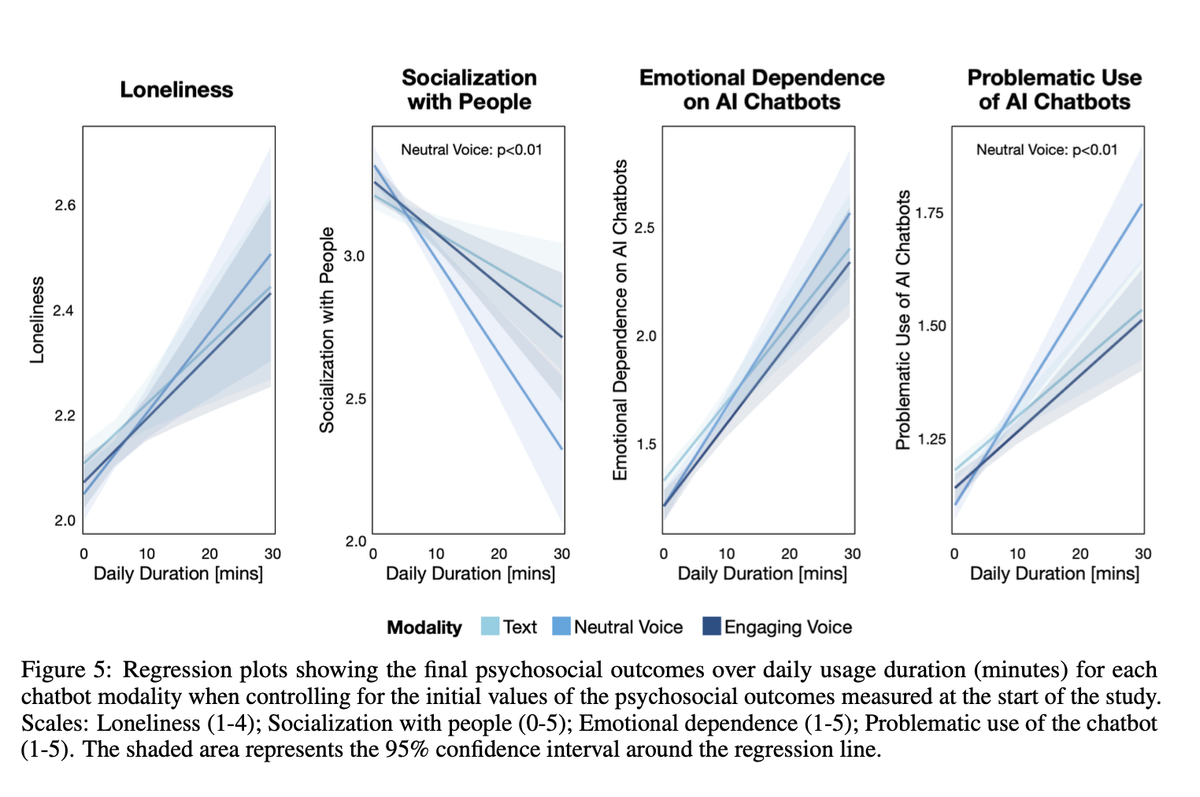
本文分析了Waymo自动驾驶汽车在2024年7月至2025年2月期间发生的38起严重事故。令人惊讶的是,其中绝大多数事故并非Waymo车辆自身原因造成,而是由其他车辆违规驾驶导致,例如超速、闯红灯等。Waymo的数据显示,其自动驾驶车辆的事故率远低于人类驾驶员,即使将所有事故都归咎于Waymo,其安全记录依然显著优于人类驾驶。与人类驾驶相比,Waymo在减少事故方面取得了显著进展,尤其是在减少导致人员受伤的事故方面。
AI