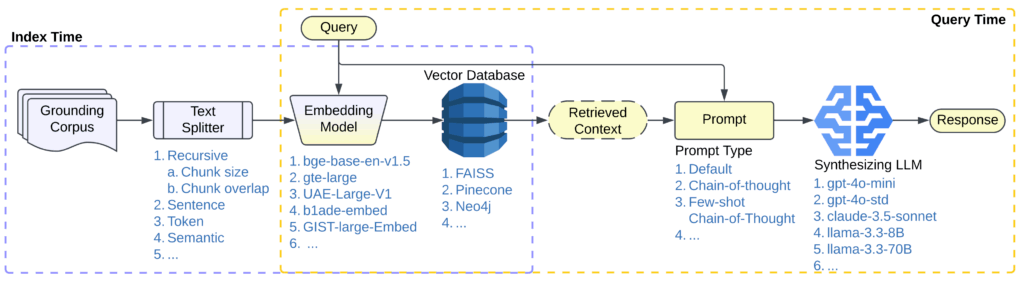
Memvid : Révolutionner la mémoire de l'IA avec des vidéos
Memvid révolutionne la gestion de la mémoire de l'IA en codant les données textuelles en vidéos, permettant une recherche sémantique ultrarapide sur des millions de fragments de texte avec des temps de récupération inférieurs à la seconde. Contrairement aux bases de données vectorielles traditionnelles qui consomment des quantités massives de RAM et de stockage, Memvid compresse votre base de connaissances en fichiers vidéo compacts tout en maintenant un accès instantané à toute information. Il prend en charge l'importation de PDF, plusieurs LLM, un fonctionnement en mode hors ligne prioritaire et possède une API simple. Que vous construisiez une base de connaissances personnelle ou que vous gériez des ensembles de données massifs, Memvid offre une solution efficace et pratique, marquant une révolution dans la gestion de la mémoire de l'IA.
.webp)