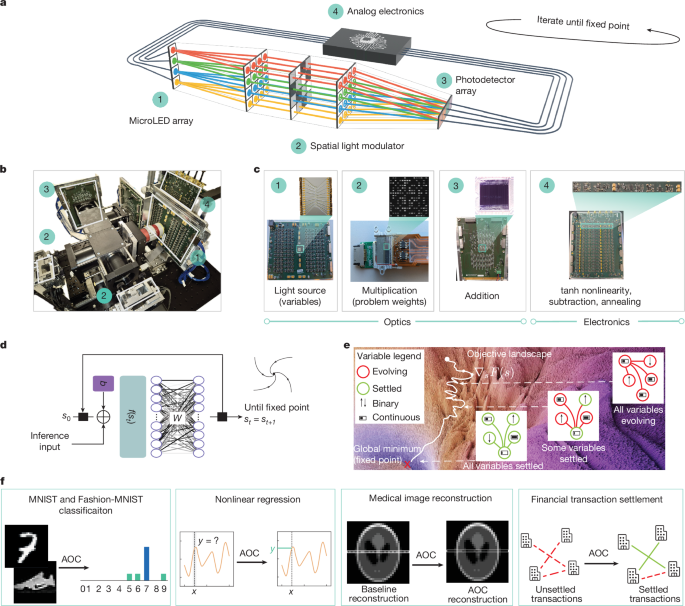
嵌入式维度:从300到4096,AI模型的进化之路
2025-09-08
几年前,200-300维的嵌入式向量在工业界很常见。但随着深度学习模型(如BERT、GPT)的兴起和GPU计算能力的提升,嵌入式向量的维度不断增长,从BERT的768维到GPT-3的1536维,再到如今的4096维甚至更高。这背后是模型架构(Transformer)、训练数据规模、以及开源平台(Hugging Face)和向量数据库的共同作用。虽然维度增加带来了性能提升,但也带来了存储和推理的挑战。最近的研究开始探索更有效的嵌入式表示方法,例如Matryoshka表示学习,以平衡性能和效率。