Databricks' TAO: Feinabstimmung übertreffen mit unbeschrifteten Daten
2025-03-26

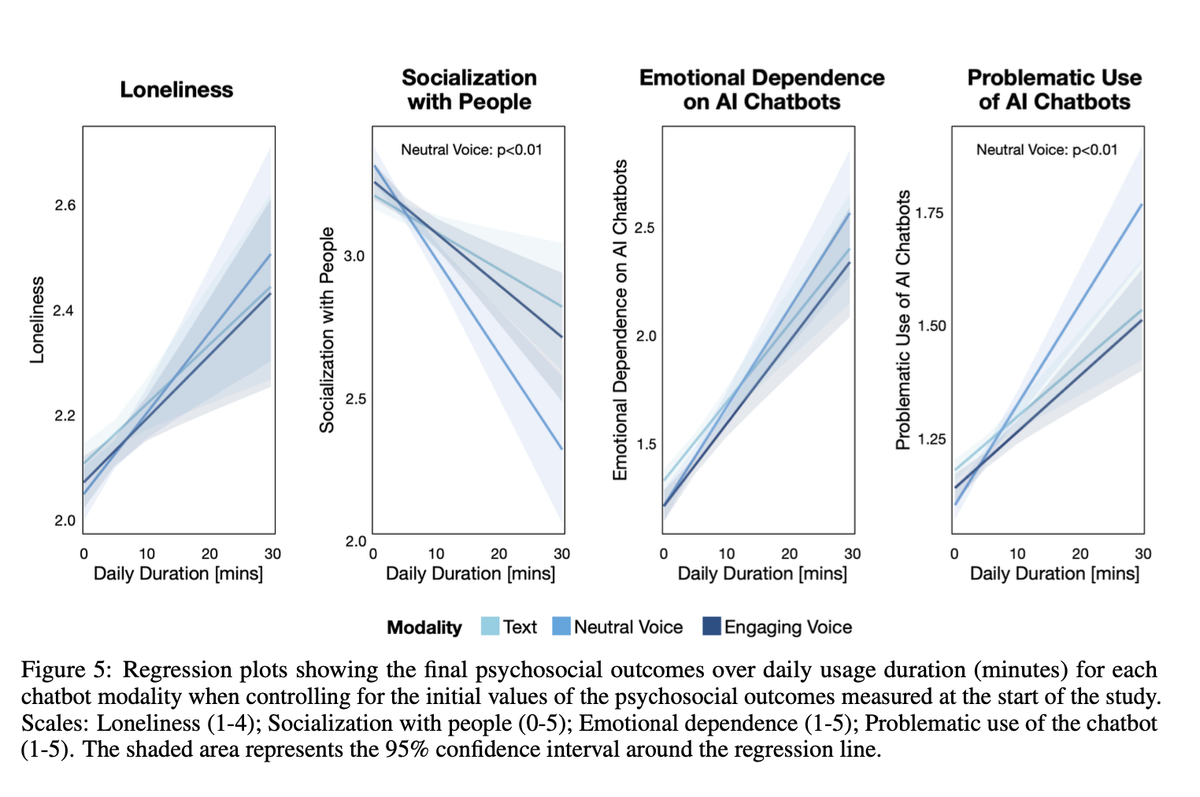
Databricks stellt TAO (Test-time Adaptive Optimization) vor, eine neue Methode zum Feintuning von Modellen, die nur unbeschriftete Nutzungsdaten benötigt. Im Gegensatz zum traditionellen Feintuning nutzt TAO Testzeit-Rechenleistung und Reinforcement Learning, um die Modellleistung basierend auf vergangenen Eingabebeispielen zu verbessern. Überraschenderweise übertrifft TAO das traditionelle Feintuning und bringt Open-Source-Modelle wie Llama auf eine mit teuren proprietären Modellen wie GPT-4 vergleichbare Qualität. Diese Innovation ist für Databricks-Kunden in der Vorschau verfügbar und wird zukünftige Produkte antreiben.